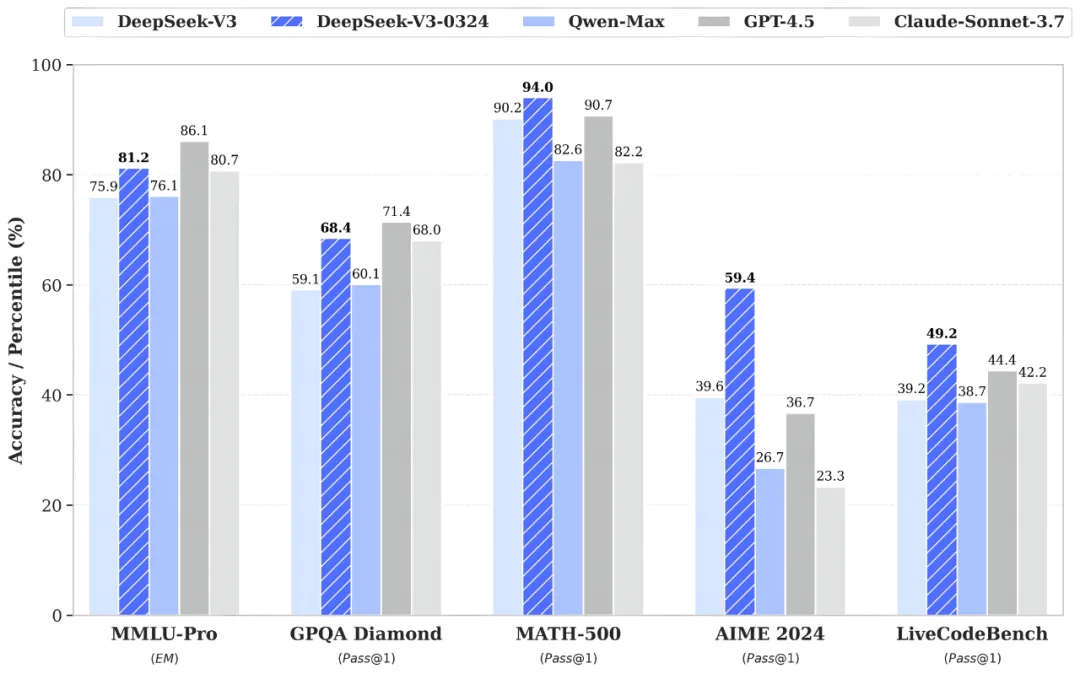
Tesla

AI is Life. We Are Empty.
目 录CONTENT

以下是
人工智能
相关的文章