




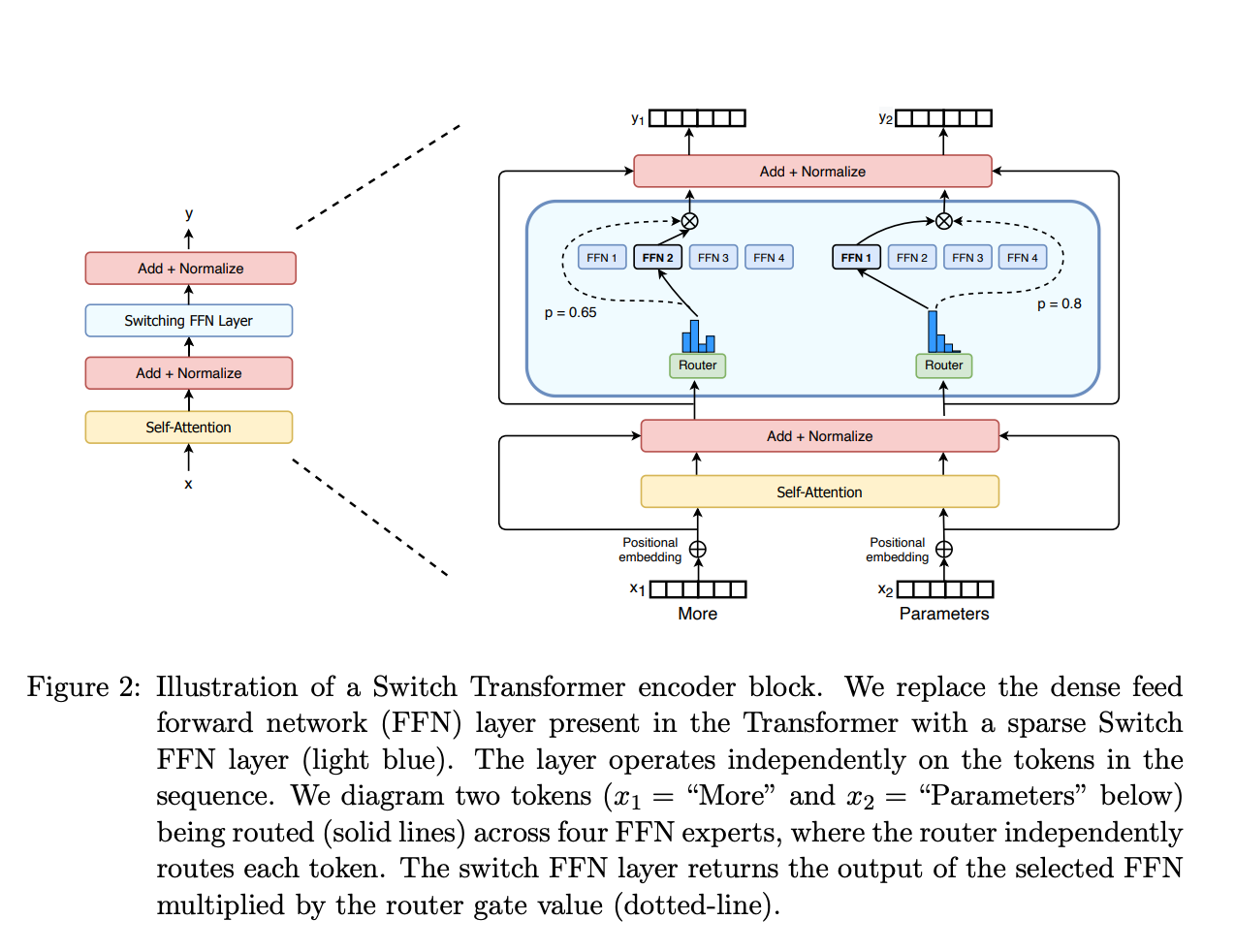
稀疏 MoE 层: 这些层代替了传统 Transformer 模型中的前馈网络 (FFN) 层。MoE 层包含若干“专家”(例如 8 个),每个专家本身是一个独立的神经网络。在实际应用中,这些专家通常是前馈网络 (FFN),但它们也可以是更复杂的网络结构,甚至可以是 MoE 层本身,从而形成层级式的 MoE 结构。
门控网络或路由: 这个部分用于决定哪些令牌 (token) 被发送到哪个专家。例如,在下图中,“More”这个令牌可能被发送到第二个专家,而“Parameters”这个令牌被发送到第一个专家。有时,一个令牌甚至可以被发送到多个专家。令牌的路由方式是 MoE 使用中的一个关键点,因为路由器由学习的参数组成,并且与网络的其他部分一同进行预训练。
优点
预训练速度更快
推理速度更快
缺点
需要参数加载到内存,需要大量显存:在 MoE 模型中,只有 FFN 层被视为独立的专家,而模型的其他参数是共享的
微调阶段泛化和过拟合
重点
稀疏计算
令牌负载均衡
Switch Transformer
评论区