




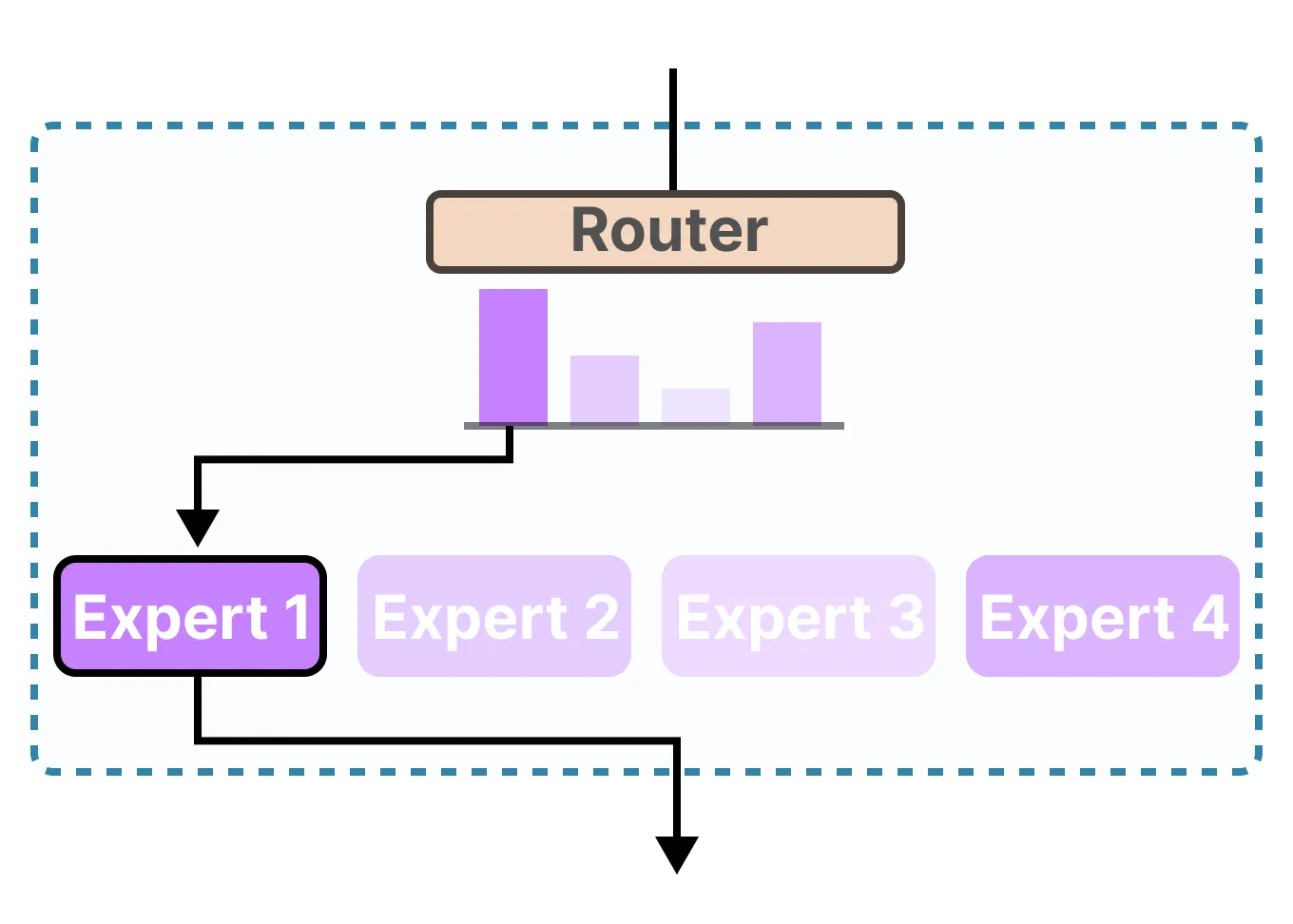
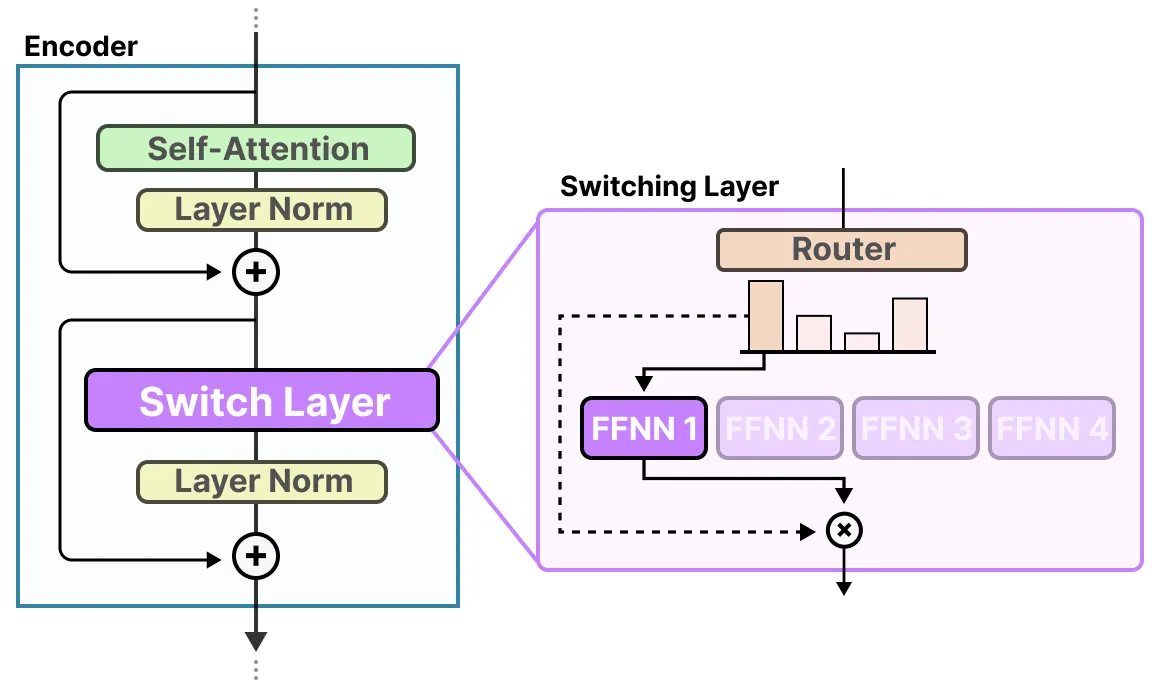
MoE的两个主要组件,即专家和路由器
Experts - Each FFNN layer now has a set of “experts” of which a subset can be chosen. These “experts” are typically FFNNs themselves.专家-每个FFNN层现在都有一组“专家”,可以选择其中的一个子集。这些“专家”通常是FFNN本身。
Router or gate network - Determines which tokens are sent to which experts.路由器或门网络 - 确定将哪些令牌发送给哪些专家。
“an “expert” is not specialized in a specific domain like “Psychology” or “Biology”. At most, it learns syntactic information on a word level instead”
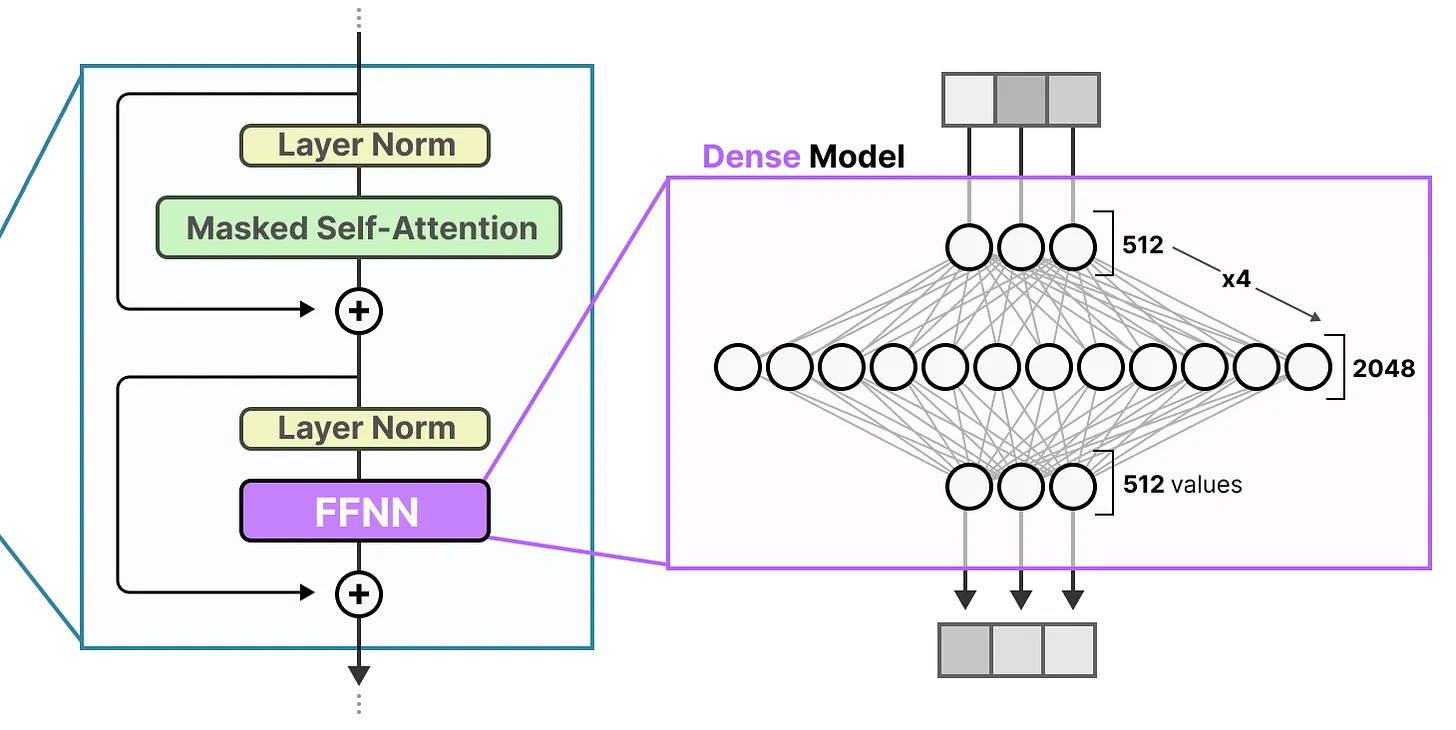
Dense Layers
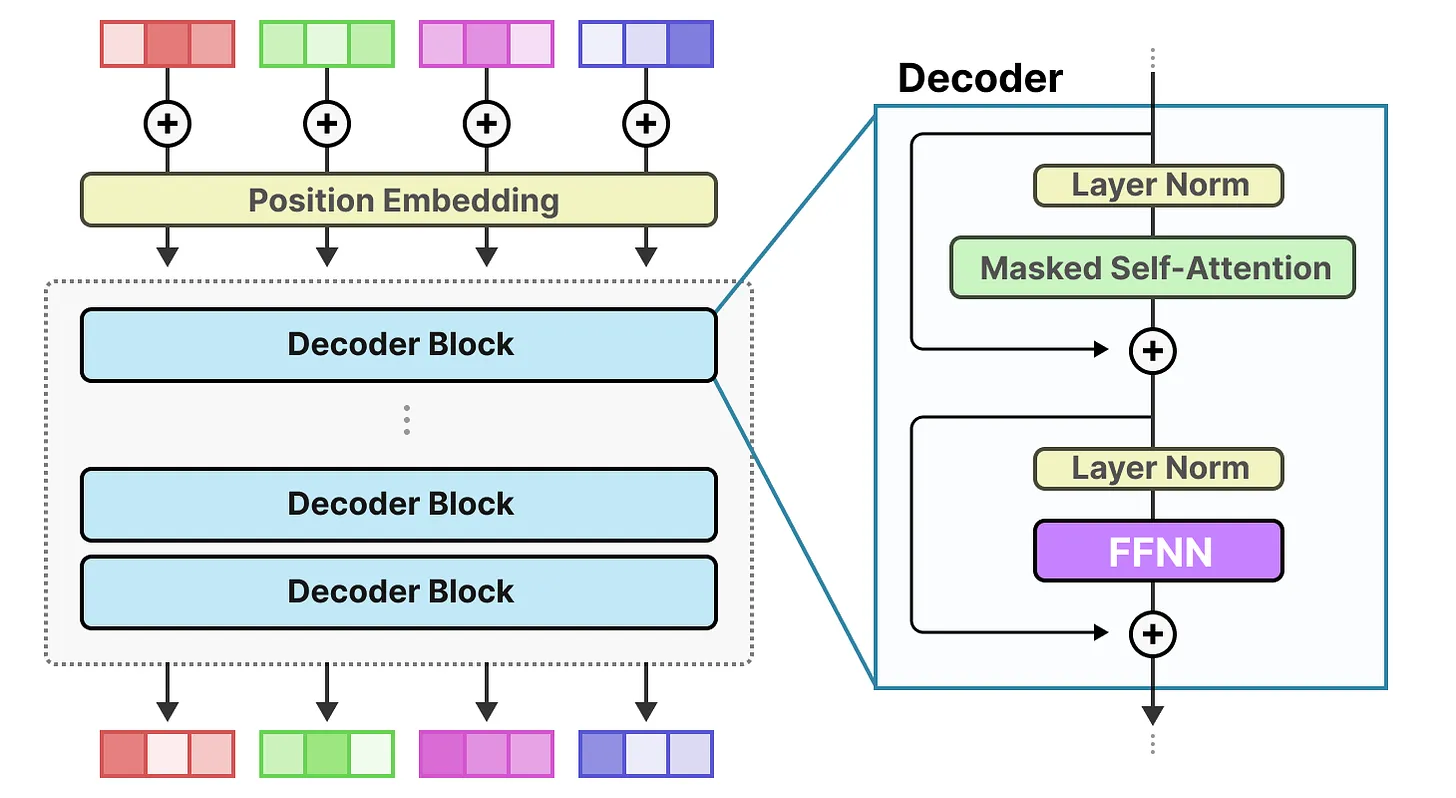
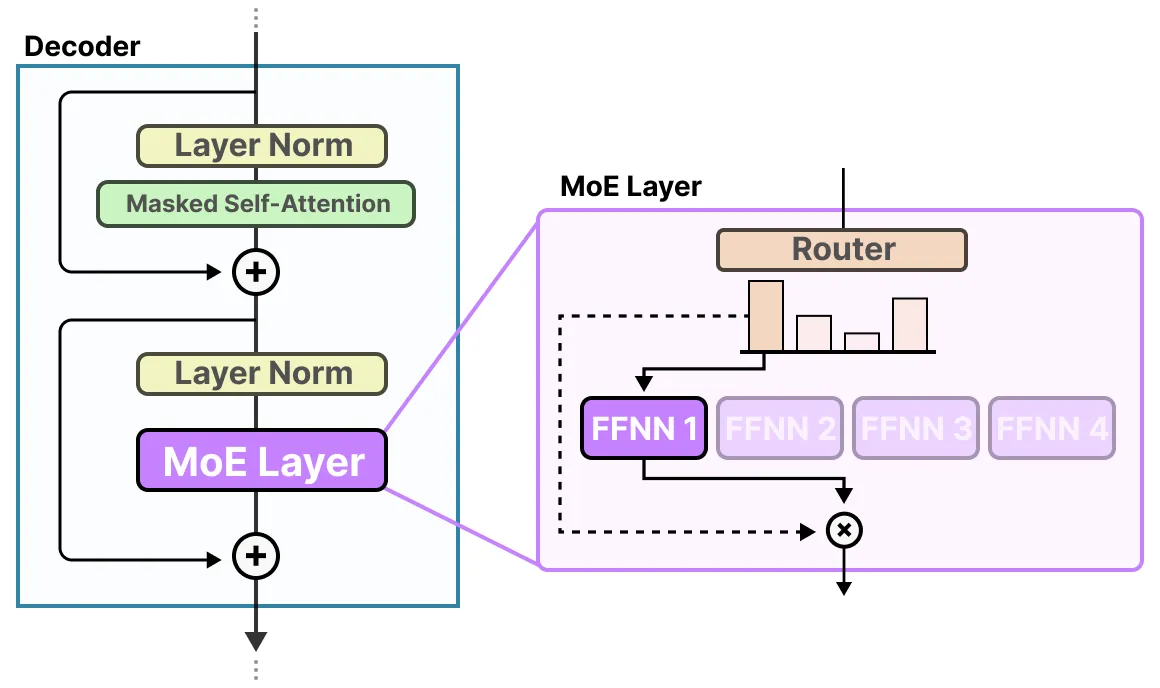
标准解码器
FFNN:前馈神经网络,允许模型使用注意力机制创建上下文,补货数据复杂关系
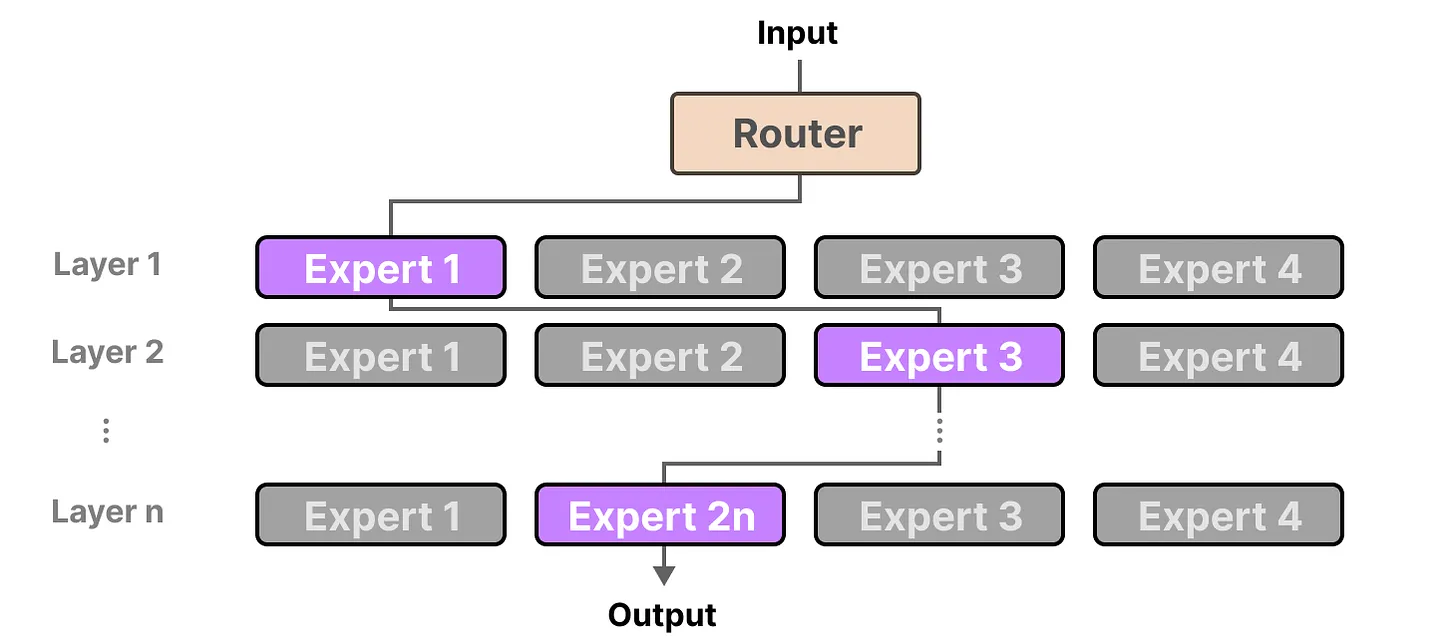
Spare Layers
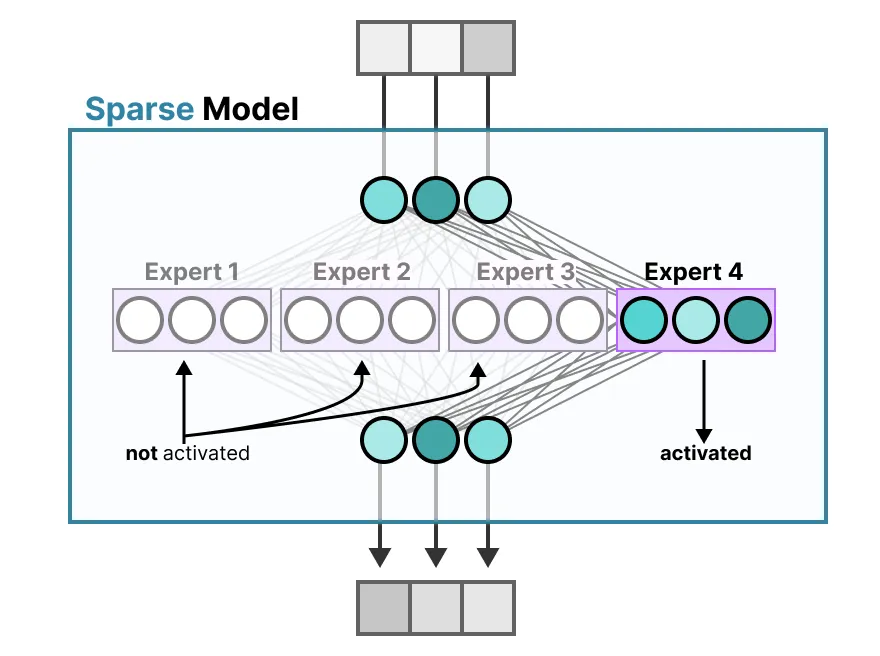
密集模型切成多个块(所谓的 experts),重新训练它,并且只在给定时间激活 EA 的子集,“
The underlying idea is that each expert learns different information during training. Then, when running inference, only specific experts are used as they are most relevant for a given task”
The FFNN in a traditional Transformer is called a dense model since all parameters (its weights and biases) are activated. Nothing is left behind and everything is used to calculate the output.
sparse models only activate a portion of their total parameters and are closely related to Mixture of Experts.

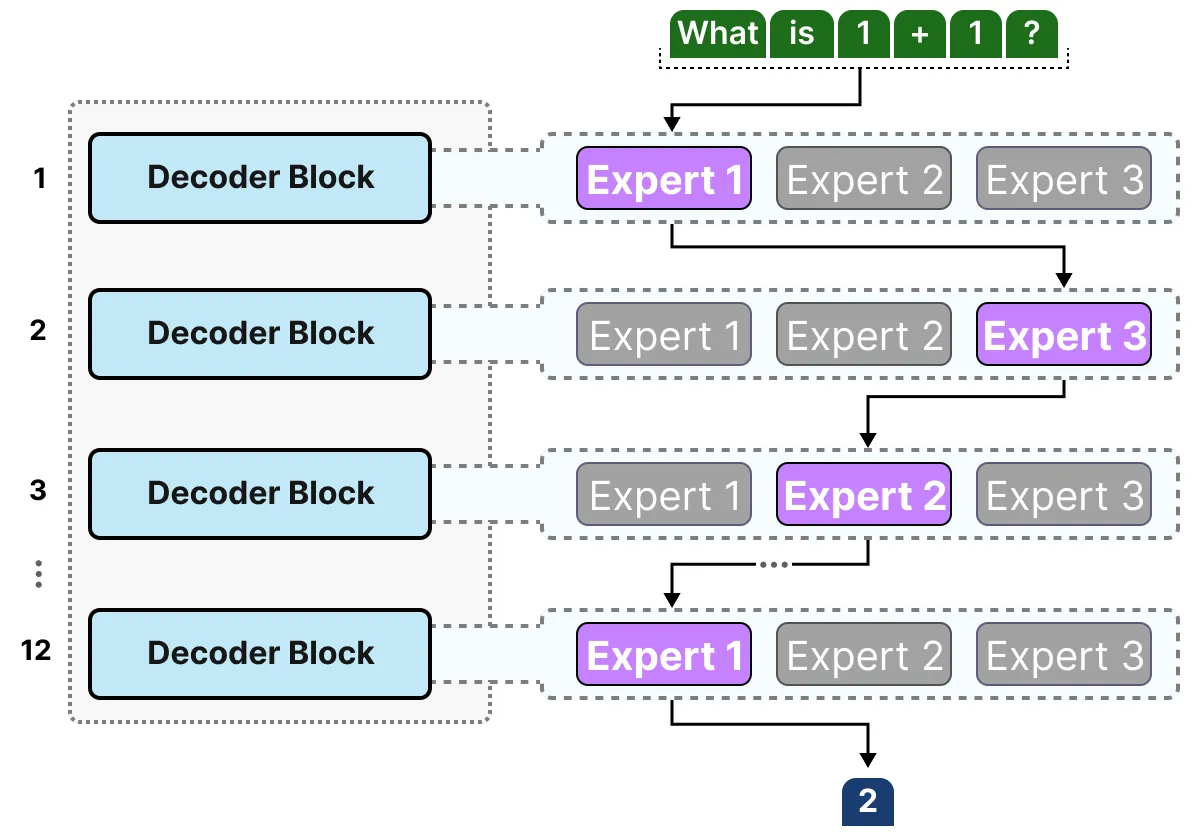
Experts in decoder models, however, do not seem to have the same type of specialization. That does not mean though that all experts are equal.
专家架构
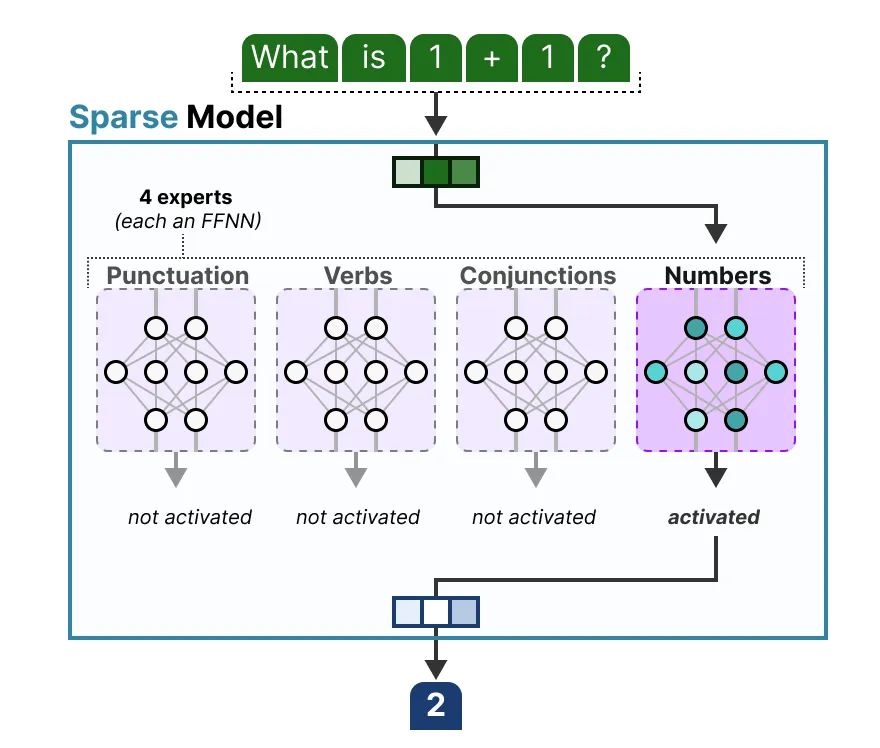
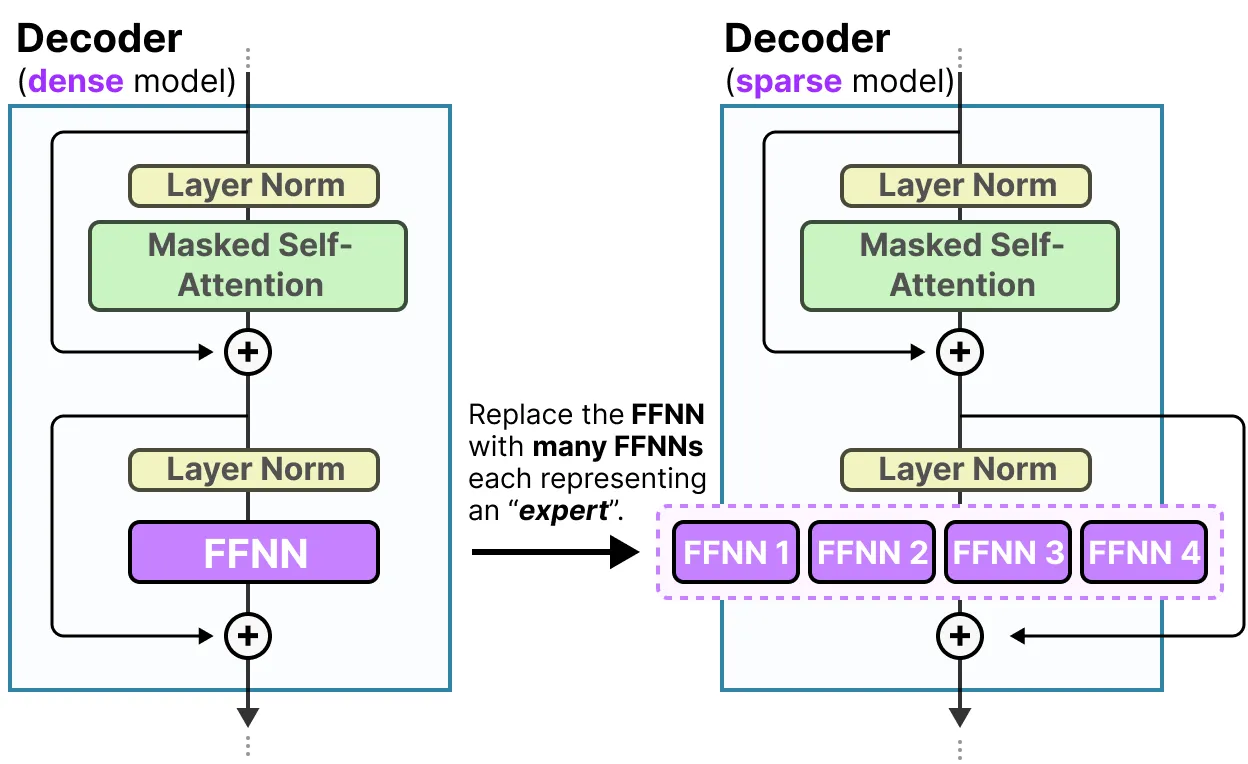
解码器的FFNN有一个变为多个FFNN,每个FFNN就是一个专家
路由
The router (or gate network) is also an FFNN and is used to choose the expert based on a particular input. It outputs probabilities which it uses to select the best matching expert:
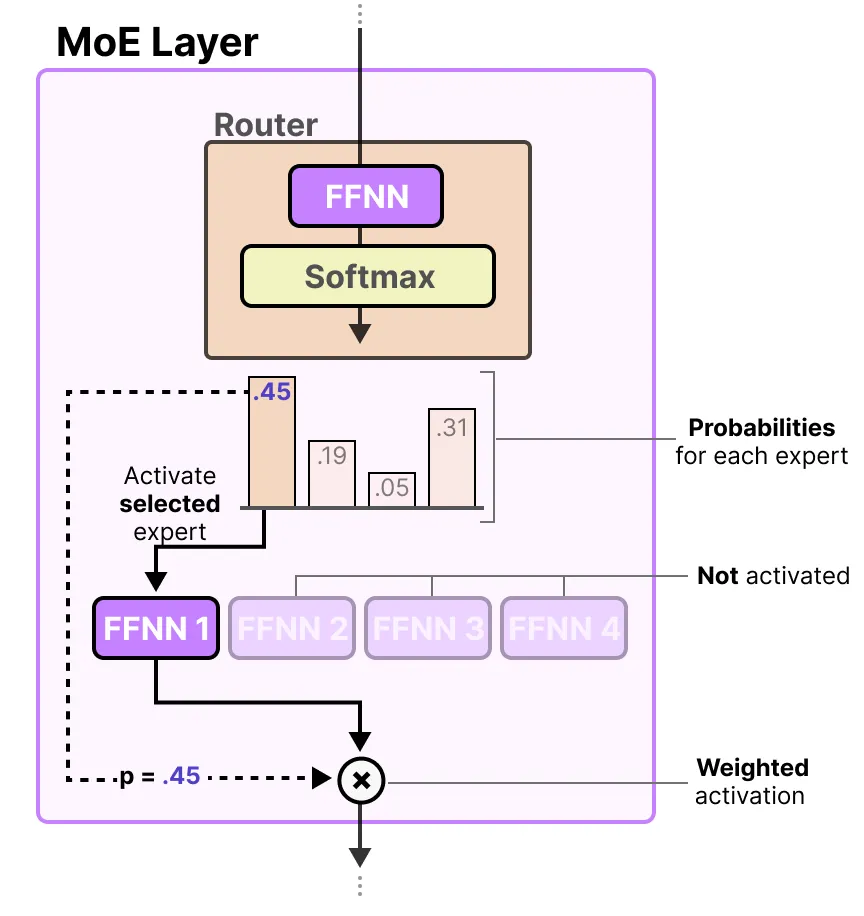
专家选择
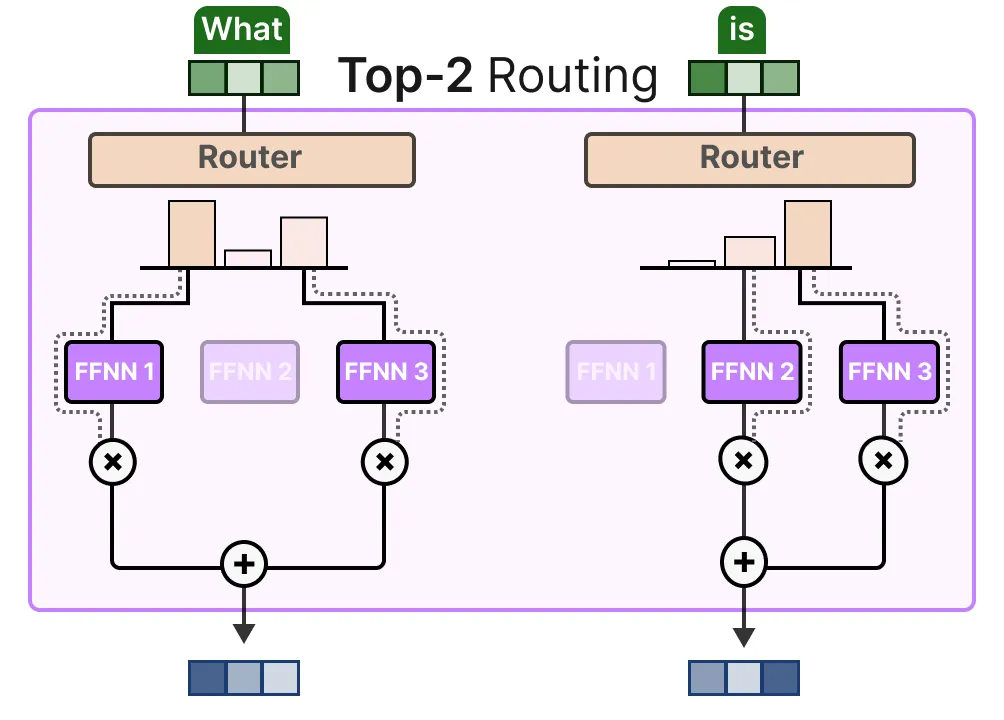
top k
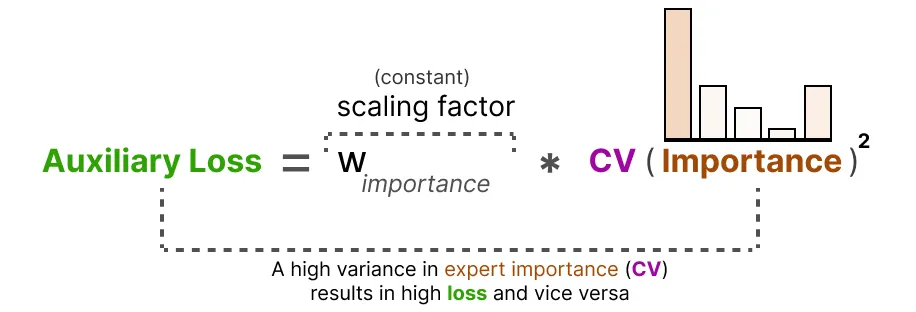
auxiliary loss
等等
简化MOE
评论区