




https://daleonai.com/transformers-explained
作者:Dale Markowitz · 2021 年 5 月 6 日

你知道那句俗语吗?当你有一把锤子时,所有东西看起来都像钉子。在机器学习中,我们似乎真的发现了一把神奇的锤子,对它来说,所有东西实际上都是钉子,它被称为 Transformers。Transformers 是可以设计来翻译文本、写诗和专栏文章,甚至生成计算机代码的模型。事实上,我在 daleonai.com 上撰写的许多令人惊叹的研究都是基于 Transformers 构建的,比如AlphaFold 2,这个模型可以根据蛋白质的基因序列预测蛋白质的结构,还有强大的自然语言处理 (NLP) 模型,如GPT-3、BERT、T5、Switch、Meena 等。你可能会说它们不仅仅是满足于......呃,忘了它吧。
如果你想在机器学习尤其是 NLP 领域保持领先地位,你必须至少了解一点 Transformers。因此,在这篇文章中,我们将讨论它们是什么、它们的工作原理以及它们为何如此有影响力。
Transformer 是一种神经网络架构。总而言之,神经网络是一种非常有效的模型,可用于分析图像、视频、音频和文本等复杂数据类型。但不同类型的神经网络针对不同类型的数据进行了优化。例如,为了分析图像,我们通常会使用卷积神经网络或“CNN”。它们大致模仿了人类大脑处理视觉信息的方式。

卷积神经网络,由 Wikicommons 的 Renanar2 提供。
自 2012 年左右以来,我们在使用 CNN 解决视觉问题方面取得了相当大的成功,例如识别照片中的物体、识别人脸和读取手写数字。但长期以来,语言任务(翻译、文本摘要、文本生成、命名实体识别等)方面没有类似的出色解决方案。这很不幸,因为语言是我们人类交流的主要方式。
在 2017 年推出 Transformer 之前,我们使用深度学习来理解文本的方式是使用一种称为循环神经网络 (RNN) 的模型,该模型如下所示:
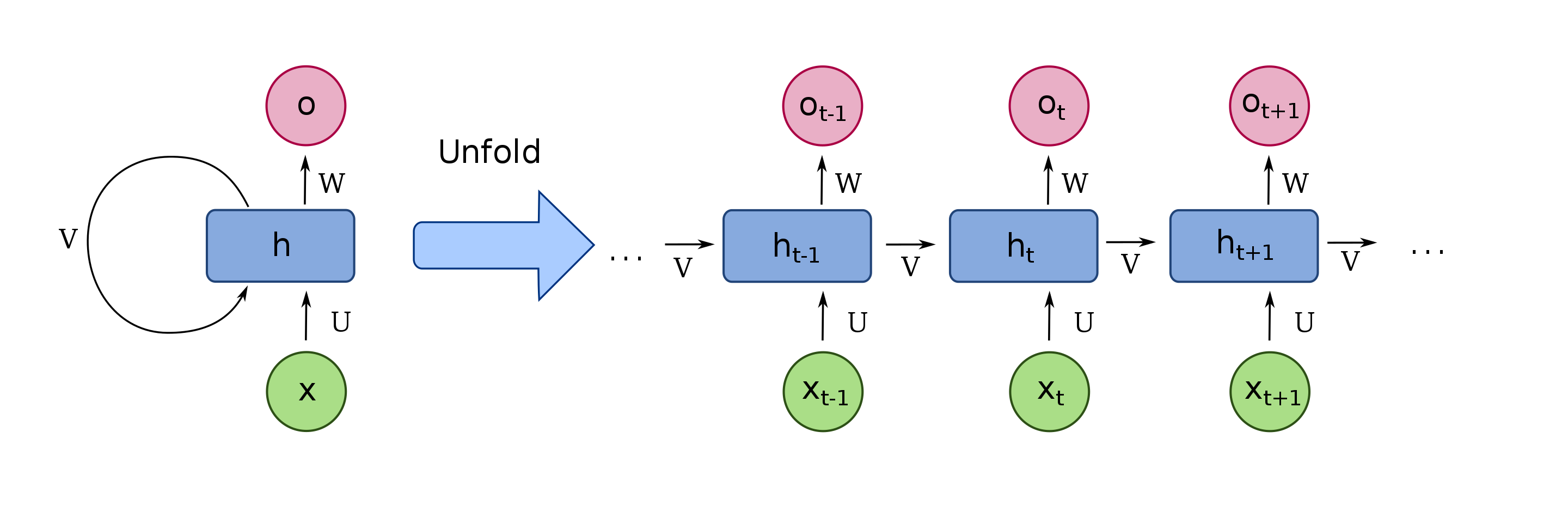
RNN 的图像,由维基百科提供。
假设你想将一个句子从英语翻译成法语。RNN 会将一个英语句子作为输入,逐个处理单词,然后按顺序输出法语单词。这里的关键词是“顺序”。在语言中,单词的顺序很重要,你不能随意打乱它们。句子:
“简是自找麻烦。”
意思和下面的句子截然不同:
“寻找简时遇到了麻烦”
因此,任何想要理解语言的模型都必须捕捉词序,而循环神经网络通过按顺序一次处理一个单词来实现这一点。
但 RNN 存在问题。首先,它们难以处理大量文本,例如长段落或文章。当读完一段文字时,它们会忘记开头的内容。例如,基于 RNN 的翻译模型可能难以记住长段落中主题的性别。
更糟糕的是,RNN 很难训练。众所周知,它们很容易受到所谓的梯度消失/爆炸问题的影响(有时你只需要重新开始训练并祈祷好运)。更成问题的是,由于 RNN 是按顺序处理单词的,因此很难并行化。这意味着你不能通过向它们投入更多 GPU 来加快训练速度,反过来,这意味着你无法在那么多数据上训练它们。
进入变压器
Transformers 就是在这里改变了一切。它们由谷歌和多伦多大学的研究人员于 2017 年开发,最初设计用于翻译。但与循环神经网络不同,Transformers 可以非常高效地并行化。这意味着,有了合适的硬件,你可以训练一些非常大的模型。
多大?
大大大大。
GPT-3 是一个令人印象深刻的文本生成模型,其书写效果几乎与人类一样好,它在约45 TB的文本数据上进行了训练,其中包括几乎所有的公共网络。
因此,如果你还记得有关 Transformers 的任何信息,那就是:将一个可以很好地扩展的模型与一个巨大的数据集结合起来,其结果可能会让你大吃一惊。
变压器如何工作?
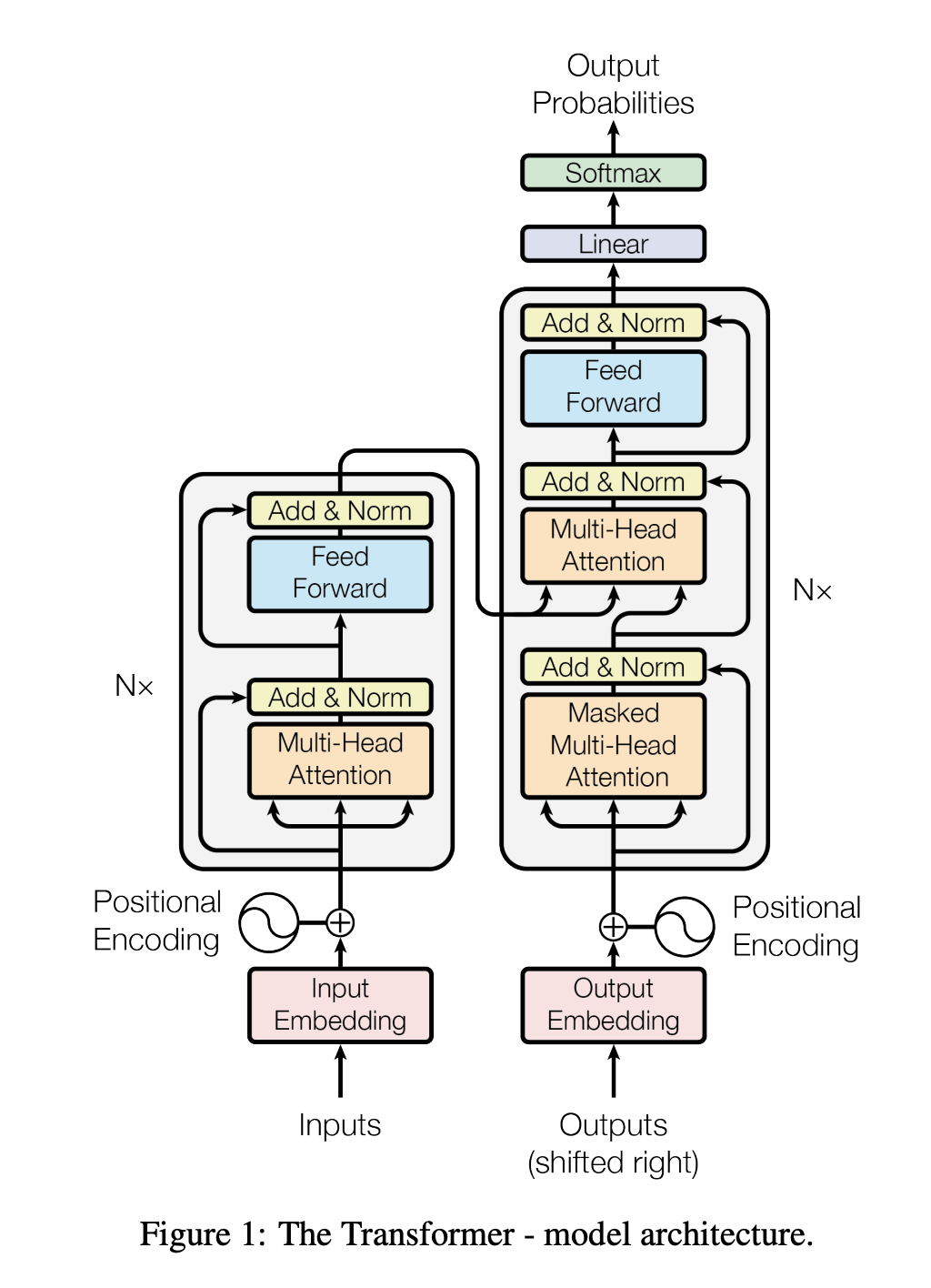
原始论文中的变压器图
虽然原始论文中的图表有点吓人,但 Transformers 背后的创新可以归结为三个主要概念:
位置编码
注意力
自注意力机制
位置编码
让我们从第一个开始,位置编码。假设我们试图将文本从英语翻译成法语。请记住,RNN,即传统的翻译方式,通过按顺序处理单词来理解词序。但这也是使它们难以并行化的原因。
Transformer 通过一种称为位置编码的创新技术解决了这一障碍。其理念是获取输入序列(在本例中为一个英文句子)中的所有单词,并为每个单词添加一个数字来表示其顺序。因此,你向网络输入如下序列:
[("Dale", 1), ("says", 2), ("hello", 3), ("world", 4)]
从概念上讲,你可以认为这是将理解词序的负担从神经网络结构转移到数据本身。
起初,在 Transformer 接受任何数据训练之前,它不知道如何解释这些位置编码。但随着模型看到越来越多的句子及其编码示例,它学会了如何有效地使用它们。
我在这里做了一些过度简化——原作者使用正弦函数来得出位置编码,而不是简单的整数 1、2、3、4——但要点是一样的。将词序存储为数据,而不是结构,你的神经网络就会变得更容易训练。
注意力
Transformers 的下一个重要部分是注意力。
了解?
注意力是一种神经网络结构,如今在机器学习中随处可见。事实上,2017 年介绍 Transformer 的论文标题并非《我们为您呈现 Transformer》 ,而是《注意力就是您所需要的一切》。
注意力机制是在两年前的 2015 年,即翻译的背景下引入的。为了理解它,我们来看看原文中的这个例句:
欧洲经济区协议于1992年8月签署。
现在想象一下尝试将该句子翻译成法语:
欧洲经济区协议于 1992 年 8 月签署。
尝试翻译该句子的一个糟糕方法是逐个检查英语句子中的单词,然后尝试逐个单词地吐出其法语对应词。这种方法效果不佳,原因有几个,但首先,法语翻译中的一些单词被颠倒了:英语中是“欧洲经济区”,但法语中是“la zone économique européenne”。此外,法语是一种有性别词的语言。形容词“économique”和“européenne”必须是阴性形式,才能与阴性宾语“la zone”匹配。
注意力机制允许文本模型在决定如何翻译输出句子中的单词时“查看”原始句子中的每个单词。以下是原始注意力论文中的精美可视化:

图片来自论文《通过联合学习对齐和翻译的神经机器翻译(2015)》
这是一种热图,显示了模型在输出法语句子中的每个单词时“关注”的位置。正如您所预料的那样,当模型输出单词“européenne”时,它会重点关注输入单词“European”和“Economic”。
那么模型如何知道在每个时间步骤中应该“关注”哪些单词呢?这是从训练数据中学到的东西。通过查看数千个法语和英语句子的例子,模型可以了解哪些类型的单词是相互依赖的。它学习如何尊重性别、复数和其他语法规则。
自 2015 年发现以来,注意力机制一直是自然语言处理中极为有用的工具,但在其原始形式中,它与循环神经网络一起使用。因此,2017 年 Transformers 论文的创新部分在于完全抛弃了 RNN。这就是为什么 2017 年的论文被称为“注意力就是你所需要的一切”。
自注意力机制
Transformer 的最后一个部分(也许是影响最大的部分)是对注意力机制的改进,称为“自我注意力”。
我们刚刚谈到的“普通”注意力类型有助于对齐英语和法语句子中的单词,这对于翻译很重要。但是,如果你不试图翻译单词,而是建立一个理解语言中潜在含义和模式的模型——一种可以用来完成任何语言任务的模型,那会怎样呢?
总的来说,神经网络之所以强大、令人兴奋和酷炫,是因为它们通常会自动为训练数据构建有意义的内部表示。例如,当你检查视觉神经网络的各层时,你会发现一组神经元可以“识别”边缘、形状,甚至眼睛和嘴巴等高级结构。用文本数据训练的模型可能会自动学习词性、语法规则以及单词是否同义词。
神经网络学习的语言内部表征越好,它在任何语言任务中的表现就越好。事实证明,如果将注意力机制应用于输入文本本身,它就可以成为一种非常有效的方法。
例如,以下两句话:
“服务员,我可以结账吗?”
“看起来我刚刚导致服务器崩溃了。”
这里的“服务器”一词含义截然不同,我们人类可以通过查看周围的单词轻松消除歧义。自注意力机制允许神经网络根据周围单词的上下文来理解单词。
因此,当模型处理第一个句子中的“服务器”一词时,它可能会“关注”“检查”一词,这有助于区分人工服务器和金属服务器。
在第二句中,模型可能会关注“崩溃”这个词,以确定这个“服务器”指的是一台机器。
自我注意力帮助神经网络消除词语歧义、进行词性标注、实体解析、学习语义角色等等。
因此,我们在这里:从 10,000 英尺的高度解释变形金刚,可以归结为:
位置编码
注意力
自注意力机制
如果您需要更深入的技术解释,我强烈建议您查看 Jay Alammar 的博客文章《The Illustrated Transformer》。
Transformer 能做什么?
最受欢迎的基于 Transformer 的模型之一是 BERT,即“Transformer 的双向编码器表示”的缩写。它是在我加入谷歌时(2018 年)由谷歌的研究人员推出的,很快就进入了几乎所有的 NLP 项目,包括谷歌搜索。
BERT 不仅指模型架构,还指经过训练的模型本身,您可以在此处免费下载和使用。它由 Google 研究人员在大量文本语料库上进行训练,已成为 NLP 的通用小刀。它可以扩展以解决一系列不同的任务,例如:
- 文本摘要
- 问答
- 分类
- 命名实体解析
- 文本相似度
- 攻击性消息/亵渎语言检测
- 理解用户查询
- 更多内容
BERT 证明,你可以构建基于未标记数据(例如从 Wikipedia 和 Reddit 抓取的文本)进行训练的非常好的语言模型,并且这些大型的“基础”模型随后可以使用特定领域的数据适应许多不同的用例。
最近,OpenAI 创建的模型GPT-3以其生成逼真文本的能力让人们大吃一惊。谷歌研究院去年推出的Meena是一个基于 Transformer 的聊天机器人(akhem,“对话代理”),可以就几乎任何话题进行引人入胜的对话(本文作者曾花了 20 分钟与 Meena 争论人类的意义)。
Transformer 还在 NLP 之外引起轰动,它可以创作音乐、根据文本描述生成图像,还可以预测蛋白质结构。
如何使用 Transformer?
现在您已经了解了 Transformers 的强大功能,您可能想知道如何在自己的应用中开始使用它们。没问题。
您可以从TensorFlow Hub下载常见的基于 Transformer 的模型,例如 BERT 。有关代码教程,请查看我编写的有关构建由语义语言驱动的应用程序的教程。
但如果你想真正赶上潮流,并且用 Python 写代码,我强烈推荐由HuggingFace公司维护的流行“Transformers”库。该平台允许你以对开发人员非常友好的方式训练和使用当今大多数流行的 NLP 模型,如 BERT、Roberta、T5、GPT-2。
如果您想了解有关使用 Transformers 构建应用程序的更多信息,请尽快回来!更多教程即将推出。
特别感谢 Luiz/Gus Gustavo、Karl Weinmeister 和 Alex Ku 审阅本文的初稿!
评论区