




https://microsoft.github.io/generative-ai-for-beginners/#/03-using-generative-ai-responsibly/translations/cn/README?wt.mc_id=academic-105485-koreyst
人们很容易对人工智能尤其是生成式人工智能着迷,但你需要考虑如何负责任地使用它。 你需要考虑如何确保输出是公平的、无害的等等。 本章旨在为您提供上述相关背景信息、需要考虑的事项以及如何采取积极措施来改善人工智能的使用
构建生成式人工智能应用程序时负责任的人工智能的重要性。
在构建生成式 AI 应用程序时何时思考和应用 Responsible AI 的核心原则。
您可以使用哪些工具和策略来将 Responsible AI 的概念付诸实践。
原则
使用负责任的人工智能的原则:公平、包容、可靠性/安全、安全和隐私、透明度和问责制
生成式人工智能的独特性在于它能够为用户创建有用的答案、信息、指导和内容。 无需许多手动步骤即可完成此操作,这可以带来非常令人印象深刻的结果。 不幸的是如果没有适当的规划和策略,它也可能会给您的用户、产品和整个社会带来一些有害的结果
幻觉
幻觉是一个术语,用于描述 LLMs 产生的内容要么完全无意义,要么根据给出其他错误的信息
给出了一个非常确切的答案。 不幸的是,这是不正确的。 即使极少了解,人们也会发现泰坦尼克号幸存者不止一名。 但对于刚开始研究这个领域的学生来说,这个答案足以有说服力,不会被质疑并被视为事实。 这样做的后果可能会导致人工智能系统不可靠,并对我们初创公司的声誉产生负面影响。
在任何给定的 LLMs 的每次迭代中,我们都看到了在最大限度地减少幻觉方面的性能改进。 即使有了这样的改进,我们作为应用程序构建者和用户仍然需要意识到这些限制。
有害内容
模型产生有害内容。
有害内容可以定义为:
提供指示或鼓励自残或伤害某些群体。
仇恨或侮辱性内容。
指导策划任何类型的攻击或暴力行为。
提供有关如何查找非法内容或实施非法行为的说明。
展示露骨的色情内容。
不公平
“确保人工智能系统没有偏见和歧视,并公平、平等地对待每个人。” 在生成式人工智能的世界中,我们希望确保模型的输出不会强化边缘群体的排他性世界观
始终牢记广泛且多样化的用户群
方式
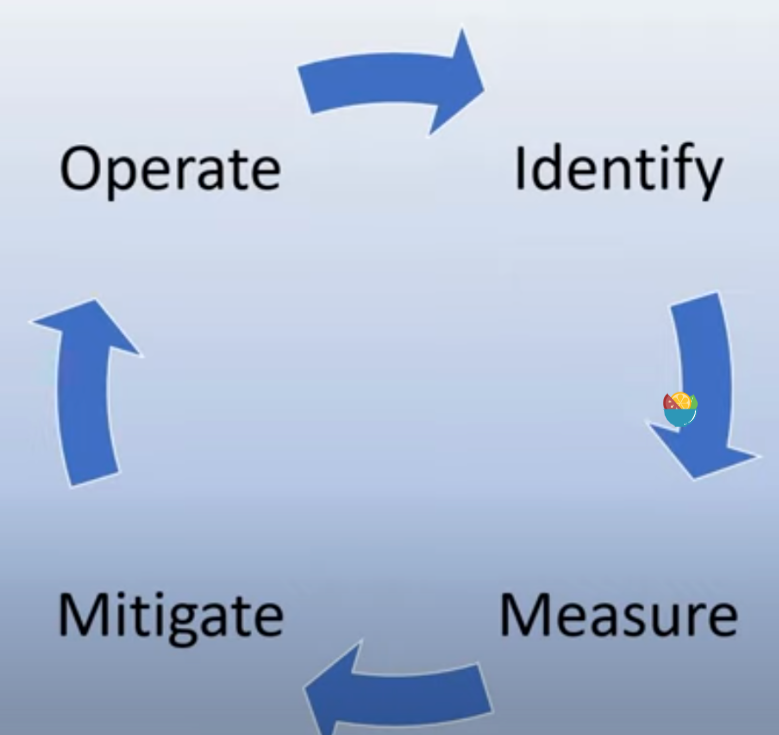
在软件测试中,我们测试用户对应用程序的预期操作,衡量潜在危害
在软件测试中,我们测试用户对应用程序的预期操作
模型。 为正确的用例选择正确的模型。 当应用于更小、更具体的用例时,更大、更复杂的模型(例如 GPT-4)可能会导致更大的有害内容风险。 使用训练数据进行微调还可以降低有害内容的风险。
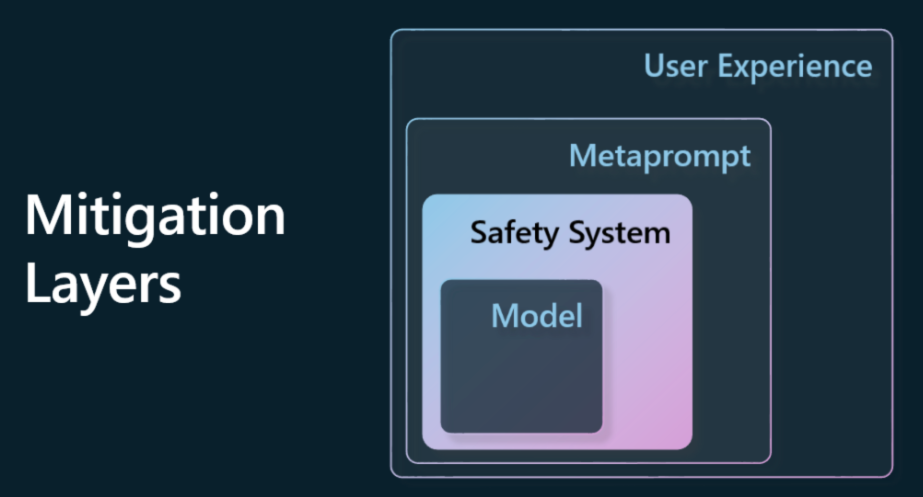
安全系统。 安全系统是平台上为模型服务的一组工具和配置,有助于减轻伤害。 Azure OpenAI Service 上的内容过滤系统就是一个例子。 系统还应该检测越狱攻击和不需要的活动,例如来自网络机器人的请求。
元提示。 元提示和基础是我们可以根据某些行为和信息指导或限制模型的方法。 这可以使用系统输入来定义模型的某些限制。 此外,提供与系统范围或领域更相关的输出。
它还可以使用检索增强生成 (RAG) 等技术,让模型仅从选定的可信来源中提取信息。
用户体验。 最后一层是用户通过应用程序界面以某种方式直接与模型交互的地方。 通过这种方式,我们可以设计 UI/UX 来限制用户可以发送到模型的输入类型以及向用户显示的文本或图像。 在部署人工智能应用程序时,我们还必须透明地了解我们的生成式人工智能应用程序可以做什么和不能做什么。
评估模型。 与 LLMs 合作可能具有挑战性,因为我们并不总是能够控制模型训练的数据。 无论如何,我们应该始终评估模型的性能和输出。 衡量模型的准确性、相似性、基础性和输出的相关性仍然很重要。 这有助于为应用相关人员和用户提供透明度和信任
运营
在发布之前,我们还希望围绕交付、处理事件和回滚制定计划,以防止扩大对用户造成的任何伤害
评论区