




本文档介绍如何使用MaxKB和Ollama搭建一个问答知识库。
1 MaxKB介绍
MaxKB是一款开源的,基于LLM大语言模型的知识库问答系统。有以下特点:
● 多模型支持:支持对接主流的大模型,包括本地私有大模型(如Llama 2,Qwen等),以及在线的OpenAI、通义千问、Kimi、Azure OpenAI和百度千帆大模型等;
● 开箱即用:支持直接上传文档、自动爬去在线文档,支持文本自动拆分、向量化,智能问答交互体验好;
● 无缝嵌入:支持零编码快速嵌入到第三方业务系统。
1.1实现原理
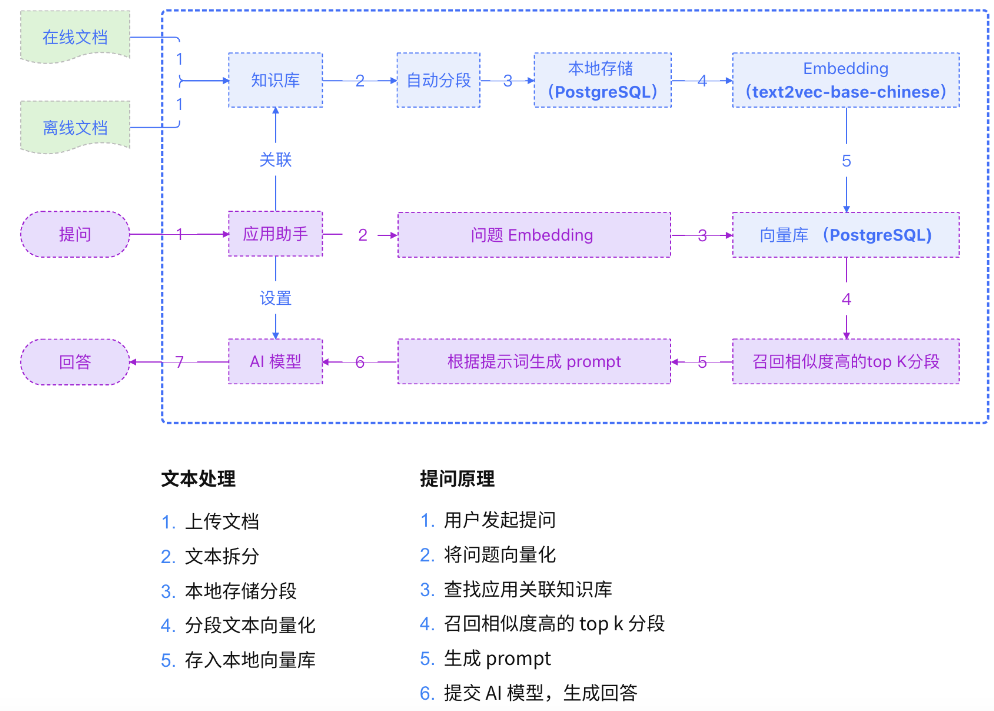
1.2部署
1.2.1环境要求
安装前确保系统符合安装条件:
● 操作系统:Ubuntu 22.04 / CentOS 7 64位系统;
● CPU/内存:推荐2C/4GB以上;
● 磁盘空间:100GB;
● 浏览器要求:请使用Chrome、FireFox、Safari、Edge等现代浏览器;
1.2.2 在线快速部署
1. MaxKB支持一键启动,仅需执行以下命令:
docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data 1panel/maxkb:v1.2.0
2. 安装成功后,可通过浏览器访问MaxKB:
http://目标服务器 IP 地址:目标端口
默认登录信息
用户名:admin
默认密码:MaxKB@123..
2 搭建Ollama本地大模型
Ollama是一个基于Go语言开发的简单易用的本地大语言模型运行框架,旨在帮助用户更容易地在本地机器上运行先进的AI模型,而不需要深入的AI或系统架构知识。
以下是Ollama的一些关键特点:
● 开源:Ollama是完全开源的,这意味着任何人都可以查看、修改和分发它的代码,这有助于促进社区的发展和持续改进。
● 开箱即用:Ollama设计得非常易于使用,通常只需要一条命令就可以启动和运行,大大减少了设置和配置的时间。
● 模型支持:Ollama 支持多种预训练的大型语言模型,包括类似 ChatGPT 这样的对话模型,以及其他类型的自然语言处理(NLP)模型。
● 模型仓库:Ollama 提供了一个模型仓库,类似于 GitHub 或 DockerHub,用于存放大语言模型。
● 本地运行:Ollama 允许模型在本地计算机上运行,这有助于保护用户的数据隐私,因为数据不会发送到远程服务器进行处理。
Ollama官网为Linux,Mac以及Windows平台各自提供了相应的安装包或一键安装脚本,这里的介绍以Linux平台为例,同时因为我需要修改一些默认配置,因此这里采用手动安装的方式。
2.1 下载Ollama文件
由于采用Go编写,Ollama可以很方便的被打包成一个二进制文件并进行分发。可以直接下载并放入对应的PATH路径:
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
2.2 将Ollama添加为自启动服务
1. 为Ollama创建用户:
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
2. 创建服务配置文件/etc/systemd/system/ollama.service,这里我加了环境变量OLLAMA_HOST让服务绑定到0.0.0.0,OLLAMA_MODELS来修改下载的大模型的存储路径。
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
Environment="OLLAMA_HOST=0.0.0.0" "OLLAMA_MODELS=/data/ollama/models"
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
3. 添加开机自启动:
sudo systemctl daemon-reload
sudo systemctl enable ollama
2.3 安装驱动(可选)
这一步主要是安装显卡驱动,比如Nvidia的CUDA,或是Radeon的ROCm。由于我的机器不带独立显卡,这一步暂时跳过,后续有需要再补充。
2.4 启动Ollama
使用systemd启动Ollama,启动成功后,Ollama会在本地启动一个restapi服务,默认监听在xx端口:
sudo systemctl start ollama
2.5 安装大模型
在比较一些问题的回答之后,这里我选择通义千问的qwen:7b作为将要使用的离线大模型。这里的7b通常指的是模型的餐数量,单位是十亿(Billion)。参数是机器学习模型中的变量,用于存储模型在训练过程中学到的知识。通常,餐数量越大的模型,其学习能力越强,能够捕捉更复杂的数据模式和关系,在特定的任务上能够达到更高的准确率,但在模型推理时,更大的模型通常也会需要更多的计算时间和资源。
1. 下载大模型:
ollama pull qwen:7b
2. 验证模型是否安装成功:
3 创建知识库问答应用
3.1 添加Ollama模型
登录MaxKB系统,菜单栏选择【系统设置】,然后选择【模型设置】,供应商选【Ollama】,点击【添加模型】,进入Ollama表单。
● 模型名称:MaxKB中自定义的模型名称。
● 模型类型:大语言模型。
● 基础模型:Ollama支持的LLM模型,支持自定义输入,但需要与Ollama支持的模型名称保持一致,如果事先没下载模型,系统会自动下载部署模型。
● API域名和API Key:填写Ollama的服务地址(如:http://192.168.0.131:11434)。没有设置过API Key的话,可以输入任意字符。192.168.0.13为本机地址
最后点击【添加】后,校验通过则添加成功,便可以在应用的AI模型列表选择该模型。
3.2 创建知识库
打开【知识库】页面,点击【创建知识库】,进入创建知识库页面,输入知识库名称、知识库描述。然后将离线文档通过拖拽或选择文件上传方式进行上传,点击【创建并导入】完成上传。
后续的分段规则直接设置为系统推荐的【智能分段】即可。
3.3 创建应用
在菜单栏选择【应用】,点击【创建应用】,进入创建应用页面,左侧为应用信息,右侧为调试预览界面。
● 应用名称:用户提问时对话框的标题和名字。
● 应用描述:对应用场景及用途的描述。
● AI模型:选择之前在【系统设置】-【模型管理】中添加的大语言模型。
● 提示词:系统默认有只能知识库的提示词,用户可以自定义通过调整提示词的内容,可以引导大模型的聊天方向。
● 多轮对话:开启时当用户提问携带用户在当前会话中最后3个问题;不开启则仅向大模型提交当前问题。
● 开场白:用户打开对话时,系统弹出的问候语。支持Markdown格式;[-]后的内容为快捷问题,一行一个。
● 问题优化:对用户提出的问题先进行一次LLM优化处理,将优化后的问题在知识库中进行向量化检索;开启后能提高检索的准确度,但由于多一次询问大模型会增加问题的时长。
应用信息设置完成后,可以在右侧调试预览中进行提问预览,调试预览中提问内容不计入对话日志。
评论区