




Qdrant部分概念
Colletion
集合是点的命名集合(带有有效载荷的向量),可以在其中进行搜索。同一集合中每个点的向量必须具有相同的维度,并使用单一指标进行比较。命名向量可用于在单个点中包含多个向量,每个向量可以有自己的维度和指标要求。
距离指标用于衡量向量之间的相似性。指标的选择取决于获取向量的方式,特别是神经网络编码器训练的方法。
Qdrant 支持以下最常见的指标类型
点积:Dot - [维基]
余弦相似度:Cosine - [维基]
欧几里得距离:Euclid - [维基]
曼哈顿距离:Manhattan - [维基]
每个集合还使用自己的参数集,用于控制集合优化、索引构建和空间清理。这些设置可以通过相应的请求随时更改
Pont
// This is a simple point
{
"id": 129,
"vector": [0.1, 0.2, 0.3, 0.4],
"payload": {"color": "red"},
}
分别在向量搜索和向量过滤阶段使用
支持使用64位无符号整数和UUID作为点ID
向量
Qdrant 中的每个点可以有一个或多个vector

将不止一种类型的向量附加到单个点
密集向量
// A piece of a real-world dense vector
[
-0.013052909,
0.020387933,
-0.007869,
-0.11111383,
-0.030188112,
-0.0053388323,
0.0010654867,
0.072027855,
-0.04167721,
0.014839341,
-0.032948174,
-0.062975034,
-0.024837125,
....
]
稀疏向量
多向量
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
vector=[
[-0.013, 0.020, -0.007, -0.111],
[-0.030, -0.055, 0.001, 0.072],
[-0.041, 0.014, -0.032, -0.062]
],
)
],
)
命名向量
支持插入多个向量到一个点
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.create_collection(
collection_name="{collection_name}",
vectors_config={
"image": models.VectorParams(size=4, distance=models.Distance.DOT),
"text": models.VectorParams(size=5, distance=models.Distance.COSINE),
},
sparse_vectors_config={"text-sparse": models.SparseVectorParams()},
)
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
vector={
"image": [0.9, 0.1, 0.1, 0.2],
"text": [0.4, 0.7, 0.1, 0.8, 0.1],
"text-sparse": {
"indices": [1, 3, 5, 7],
"values": [0.1, 0.2, 0.3, 0.4],
},
},
),
],
)
from qdrant_client import QdrantClient
client = QdrantClient(url="http://localhost:6333")
client.query_points(
collection_name="{collection_name}",
query=[0.2, 0.1, 0.9, 0.7],
using="image",
limit=3,
)
payload
和向量有关的附加信息
{
"name": "jacket",
"colors": ["red", "blue"],
"count": 10,
"price": 11.99,
"locations": [
{
"lon": 52.5200,
"lat": 13.4050
}
],
"reviews": [
{
"user": "alice",
"score": 4
},
{
"user": "bob",
"score": 5
}
]
}
from qdrant_client import QdrantClient, models
client = QdrantClient(url="http://localhost:6333")
client.upsert(
collection_name="{collection_name}",
points=[
models.PointStruct(
id=1,
vector=[0.05, 0.61, 0.76, 0.74],
payload={
"city": "Berlin",
"price": 1.99,
},
),
models.PointStruct(
id=2,
vector=[0.19, 0.81, 0.75, 0.11],
payload={
"city": ["Berlin", "London"],
"price": 1.99,
},
),
models.PointStruct(
id=3,
vector=[0.36, 0.55, 0.47, 0.94],
payload={
"city": ["Berlin", "Moscow"],
"price": [1.99, 2.99],
},
),
],
)
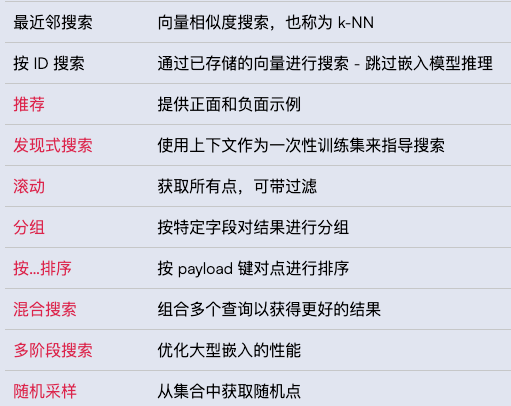
搜索
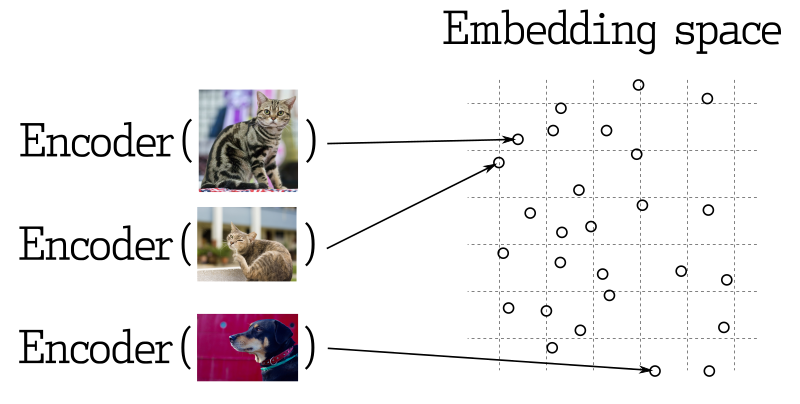
有点复杂:还没有细看
https://qdrant.org.cn/documentation/concepts/search/
过滤
使用 Qdrant,您可以在搜索或检索点时设置条件。例如,可以对点的 payload 和 id 都施加条件。
当无法在嵌入中表达对象的所有特征时,设置附加条件非常重要。例如各种业务需求:库存可用性、用户位置或期望的价格范围
优化器
没细看
Qdrant的优化器(Optimizer)是其核心组件之一,主要负责管理和优化向量索引的构建与维护,以提高搜索效率、减少资源消耗并保持系统高性能
存储
Qdrant 支持两种类型的载荷存储:内存存储 (InMemory) 和磁盘存储 (OnDisk)。
内存载荷存储的组织方式与内存向量相同。载荷数据在服务启动时加载到 RAM 中,而磁盘和 Gridstore 仅用于持久化。这种类型的存储速度相当快,但可能需要大量空间来将所有数据保存在 RAM 中,特别是当载荷附带大值时 - 例如文本摘要甚至图像。
对于大型载荷值,使用磁盘载荷存储可能更好。
一个集合内的所有数据被分成段(segments)。每个段都有独立的向量和载荷存储以及索引。
存储在段中的数据通常不重叠。但是,将同一点存储在不同的段中不会引起问题,因为搜索机制包含去重功能。
段由向量和载荷存储、向量和载荷索引以及 ID 映射器组成,ID 映射器存储内部 ID 和外部 ID 之间的关系。
根据使用的存储和索引类型,一个段可以是可附加的(appendable)或不可附加的(non-appendable)。你可以在可附加的段中自由添加、删除和查询数据。不可附加的段只能读取和删除数据。
集合中段的配置可以不同且相互独立,但一个集合中必须至少存在一个“可附加的”段
索引
载荷索引

HNSW向量索引
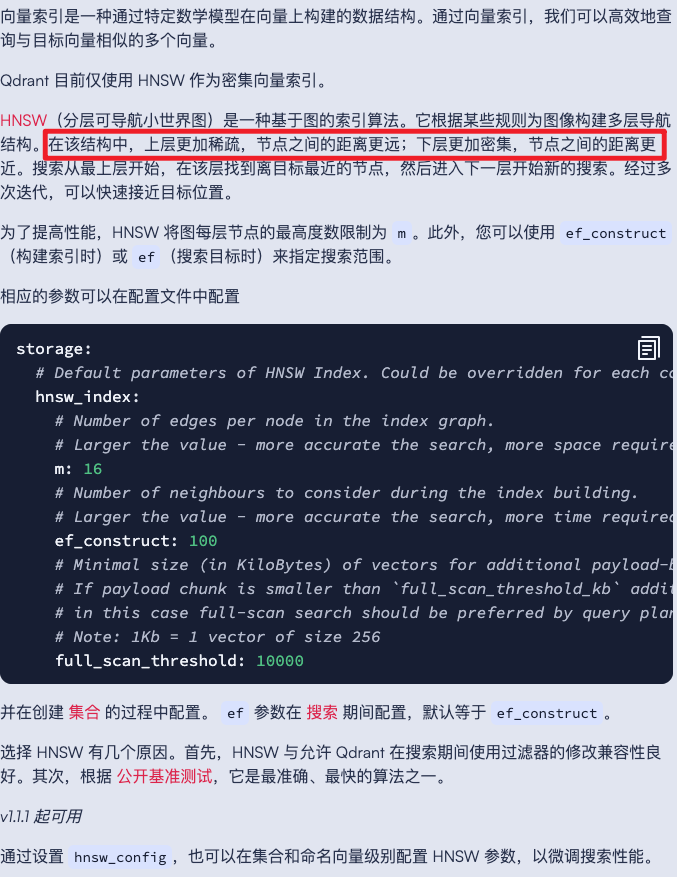
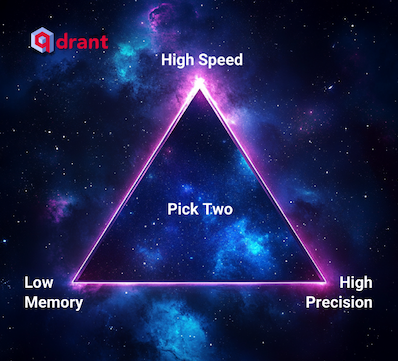
优化Qdrant性能的3种场景
https://qdrant.org.cn/documentation/guides/optimize/
高速搜索和低内存使用
高精度和低内存使用
高精度和高速搜索
评论区