




字数 2613,阅读大约需 14 分钟
Qdrant向量数据库的介绍
背景
cursor
存储在远程向量数据库(Turbopuffer)中


kilo code

“Qdrant is the most advanced vector database with highest RPS, minimal latency, fast indexing, high control with accuracy, and so much more.”
向量数据库是一种相对较新的与抽象数据表示交互的方式,这些数据表示来自于深度学习结构等不透明的机器学习模型。这些表示通常被称为向量或嵌入向量,它们是用于训练机器学习模型以完成情感分析、语音识别、目标检测等任务的数据的压缩版本### RAG

什么是Qdrant
Qdrant是一个开源向量数据库,专为下一代AI应用程序设计。它是面向云原生的,并提供RESTful和gRPC API以管理嵌入。Qdrant的特性强大,支持图像、语音和视频搜索,以及与AI引擎的集成。

什么是向量数据库
什么是高维向量(High-Dimensional Vectors)?
高维向量是由许多元素组成的数字列表,每个元素都代表其所描述数据的不同特征或特性。这些向量存在于高维空间中,也就是说,根据数据的复杂程度,它们可能有几十、几百甚至上千个维度。 例如,高维向量可以表示图像的各种属性,如颜色、纹理和形状,每个维度捕捉这些属性的不同方面。

在机器学习和数据分析中,高维向量用于以结构化的方式封装复杂信息,从而实现高效计算和分析。 高维向量也更容易捕捉次要属性,从而增加了简单事实之外的复杂性。
向量数据库 vs. 向量搜索
虽然向量数据库(vector database)和向量搜索(vector search)是相似的术语,但它们的主要区别在于各自的功能和过程。向量数据库是一种完整的数据管理解决方案,而向量搜索则是一种语义搜索工具。
当你进行向量搜索时,你的查询向量将与大量的向量集合进行比较,试图找出相似之处。这种操作有时被称为相似性搜索。 与传统数据库不同,这里的目标是在短时间内找到相似的匹配项。您的数据库是您进行向量搜索的地方。 使用索引,您将享受到快如闪电的相似性搜索,从而省去分析数据的繁琐工作。
https://cloud.tencent.com/document/product/1709/95428[1]


什么是向量数据库中的索引?
向量数据库中的索引是对存储的向量进行组织和结构化的过程,以便在进行相似性搜索时高效、快速地检索数据。
索引基本上提供了一种比遍历所有不同向量更快的检索和比较信息的方法。 当你拥有数十亿的数据量时,这一点至关重要。
向量数据库建立了不同类型的索引,开发人员通常还可以添加新的索引。 由于向量数据库的主要用途是从一个向量开始,找出与之最接近的其他向量,因此在选择向量数据库时,了解和检查所用的索引和算法非常重要。
“向量索引(Vector Index)是基于某种数学模型,对向量数据构建一种时间和空间上更高效的数据结构,以便高效地查询与目标向量相似的若干个向量。当前向量化数据库支持 FLAT、HNSW、 IVF 系列向量索引方式”

ANN
Approximate nearest neighbor



倒排索引IVF:全文检索


HNSW
https://qdrant.tech/articles/filtrable-hnsw/[2]

Qdrant科普
矢量数据库是一种相对较新的方式,用于与源自不透明机器学习模型(例如深度学习架构)的抽象数据表示进行交互。这些表示通常被称为向量或嵌入,它们是用于训练机器学习模型以完成情绪分析、语音识别、对象检测等任务的数据的压缩版本
“这些新的数据库在语义搜索 和推荐系统等许多应用中表现出色,在这里,我们将了解市场上最流行和增长最快的矢量数据库之一Qdrant。”

向量数据库是一种旨在高效存储和查询高维向量的数据库。在传统的OLTP和OLAP 数据库中(如上图所示),数据以行和列的形式组织(称为表),并根据这些列中的值执行查询。然而,在某些应用中,包括图像识别、自然语言处理和推荐系统,数据通常以高维空间中的向量表示,这些向量加上 ID 和有效负载,就是我们在像 Qdrant 这样的向量数据库中存储在集合 ( Collection ) 中的元素。
例如,在图像识别系统中,一个向量可以表示一幅图像,向量的每个元素表示该像素的一个像素值或该像素的一个描述符/特性。在音乐推荐系统中,每个向量可以表示一首歌曲,向量的元素可以捕捉歌曲的特征,例如节奏、流派、歌词等等。### 为什么使用向量数据库
使用矢量数据库的其他好处包括:
高维数据的有效存储和索引。
能够处理具有数十亿数据点的大规模数据集。
支持实时分析和查询。
能够处理来自复杂数据类型(例如图像、视频和自然语言文本)的向量。
提高机器学习和人工智能应用的性能并减少延迟。
与构建定制解决方案相比,减少了开发和部署的时间和成本。
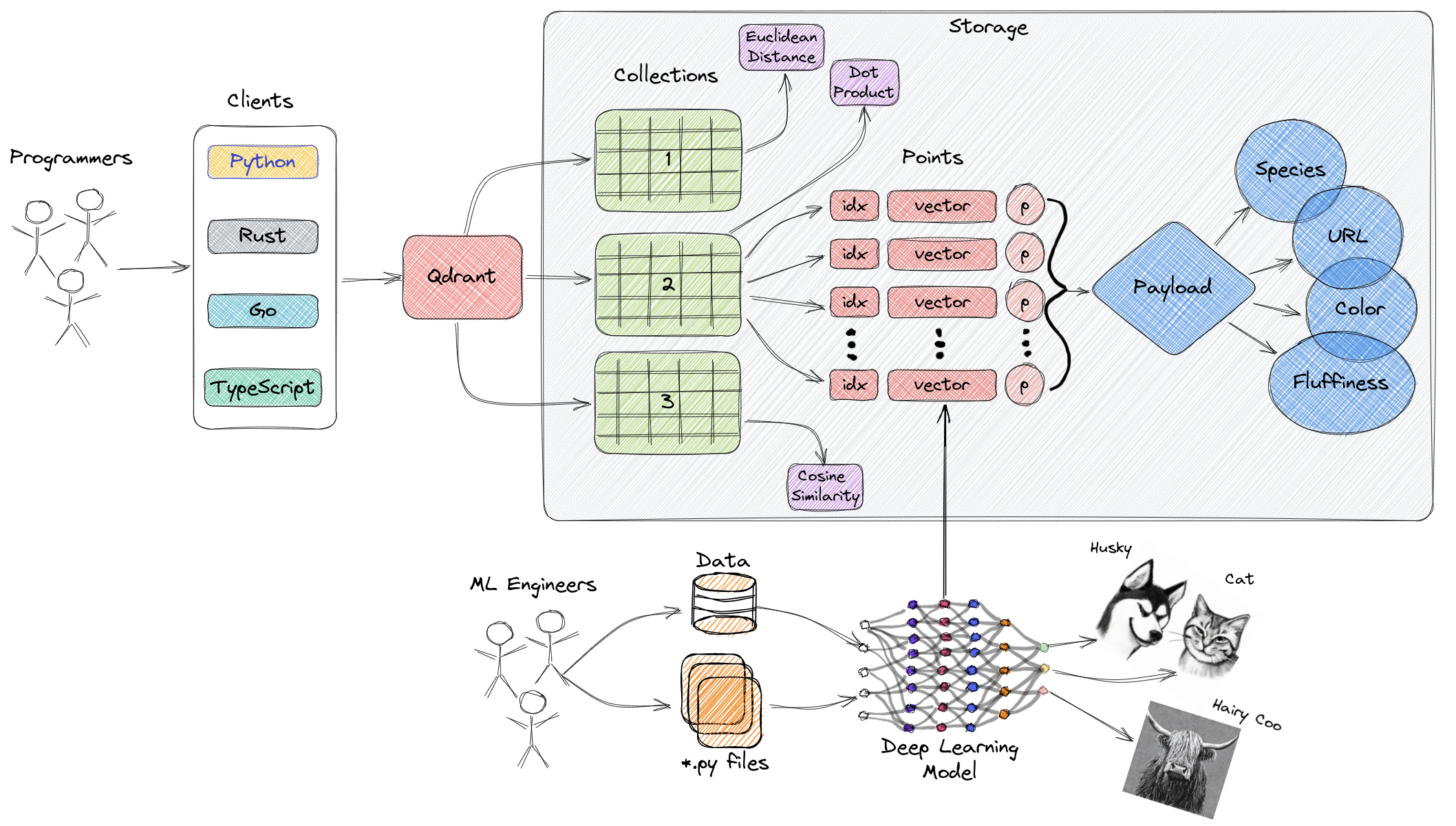
Qdrant架构

Collections: A collection is a named set of points (vectors with a payload) among which you can search. The vector of each point within the same collection must have the same dimensionality and be compared by a single metric. Named vectors can be used to have multiple vectors in a single point, each of which can have their own dimensionality and metric requirements.
Distance Metrics: These are used to measure similarities among vectors and they must be selected at the same time you are creating a collection. The choice of metric depends on the way the vectors were obtained and, in particular, on the neural network that will be used to encode new queries.
Points: The points are the central entity that Qdrant operates with and they consist of a vector and an optional id and payload.
id: a unique identifier for your vectors.
Vector: a high-dimensional representation of data, for example, an image, a sound, a document, a video, etc.
Payload: A payload is a JSON object with additional data you can add to a vector.
Storage: Qdrant can use one of two options for storage, In-memory storage (Stores all vectors in RAM, has the highest speed since disk access is required only for persistence), or Memmap storage, (creates a virtual address space associated with the file on disk).
Clients: the programming languages you can use to connect to Qdrant.
高级压缩
通过独特的二进制量化,减少内存使用
二进制量化 (BQ) 可将任何浮点数的向量嵌入转换为二进制或布尔值的向量

1536 个元素的向量。这意味着每个向量本身就占用 6kB 的空间

1、将所有“完整”向量存储在磁盘上。
2、将二进制嵌入设置为 RAM中使用### 云原生
支持在云服务厂商托管云服务,提供分配多租户等功能
易用的API


部署和使用
见单独一节
搜索

VectorData 测试

在矢量数据库测试中,官方公布的测试性能

Python 客户端将数据上传到服务器,等待所有所需索引构建完成,然后使用配置的线程数执行搜索### 测试要求
Client: 8 vcpus, 16 GiB memory, 64GiB storage (Standard D8ls v5 on Azure Cloud)
Server: 8 vcpus, 32 GiB memory, 64GiB storage (Standard D8s v3 on Azure Cloud)
对服务端做内存限制,保障测试在同一基准线上, 25GB是数据集的3倍冗余空间。
We ran all the engines in docker and limited their memory to 25GB. This was used to ensure fairness by avoiding the case of some engine configs being too greedy with RAM usage. This 25 GB limit is completely fair because even to serve the largest dbpedia-openai-1M-1536-angular dataset, one hardly needs 1M * 1536 * 4bytes * 1.5 = 8.6GB of RAM (including vectors + index). Hence, we decided to provide all the engines with ~3x the requirement.
测试场景:单节点上传和搜索基准测试
RPS

RPS:Request Per Second,每秒请求数
每秒处理更多请求,但单个请求的处理时间会更长(即延迟更高)。这是 Web 应用的典型场景,多个用户同时进行搜索。测量引擎每秒处理的请求数量
延迟

快速响应单个请求,而不是并行处理多个请求。对于服务器响应时间至关重要的应用程序来说,这是一种典型的场景。自动驾驶汽车、制造机器人和其他实时系统就是这类应用的典型例子。测量每个请求的执行时间。#### 索引时间

相关测试的详情数据
https://qdrant.tech/benchmarks/results-1-100-thread-2024-06-15.json[3]
1、Qdrant无论我们选择何种精度阈值和指标,它几乎在所有场景下都能实现最高的 RPS 和最低的延迟。在其中一个数据集上,它甚至实现了 4 倍的 RPS 提升。
2、Elasticsearch在很多情况下速度已经相当快了,但在索引时间方面却非常慢。存储 10M 以上 96 维向量时,速度可能会慢 10 倍!(32 分钟 vs 5.5 小时)
3、Milvus在索引时间方面是最快的,并且保持了良好的精度。然而,当嵌入维度更高或向量数量更多时,它的 RPS 或延迟不如其他方法。
4、Redis能够实现良好的 RPS,但精度普遍较低。它在单线程下也实现了低延迟,但随着并行请求数量的增加,延迟会迅速上升。速度提升的部分原因在于其自定义协议。
5、Weaviate自上次运行以来,改进最少。
数据集地址:https://github.com/erikbern/ann-benchmarks/[4]
测试场景:过滤搜索基准 -基准
数据集地址:https://github.com/qdrant/ann-filtering-benchmark-datasets[5]
采用的算法是:HNSW

场景测试:原文
https://qdrant.tech/benchmarks/#benchmarks-faq [6]

HNSW
https://qdrant.tech/articles/filtrable-hnsw/[7]
基准测试中取得优异成绩的算法,称为 HNSW,即“分层可导航小世界”算法

引用链接
[1] https://cloud.tencent.com/document/product/1709/95428:
[2] https://qdrant.tech/articles/filtrable-hnsw/:
[3] https://qdrant.tech/benchmarks/results-1-100-thread-2024-06-15.json:
[4] https://github.com/erikbern/ann-benchmarks/:
[5] https://github.com/qdrant/ann-filtering-benchmark-datasets:
[6] https://qdrant.tech/benchmarks/#benchmarks-faq :
[7] https://qdrant.tech/articles/filtrable-hnsw/:
评论区