




五种常见JOIN
CROSS JOIN :交叉连接
INNER JOIN:内连接
LEFT OUTER JOIN:左外连接
RIGHT OUTER JOIN:右外连接
FULL OUTER JOIN:全外连接
CREATE TABLE TableA (
ID INT,
Name VARCHAR(50)
);
CREATE TABLE TableB (
ID INT,
Age INT
);
INSERT INTO TableA (ID, Name) VALUES
(1, 'Alice'),
(2, 'Bob'),
(3, 'Charlie');
INSERT INTO TableB (ID, Age) VALUES
(1, 30),
(2, 25),
(4, 40);cross join
交叉连接(CROSS JOIN)把第一个表的每一行与第二个表的每一行进行匹配。如果两个输入表分别有 x 和 y 行,则结果表有 x*y 行
生成笛卡尔积
SELECT *
FROM TableA
CROSS JOIN TableB;
ID Name ID Age
1 Alice 1 30
1 Alice 2 25
1 Alice 4 40
2 Bob 1 30
2 Bob 2 25
2 Bob 4 40
3 Charlie 1 30
3 Charlie 2 25
3 Charlie 4 40inner join
内连接(INNER JOIN)根据连接谓词结合两个表(table1 和 table2)的列值来创建一个新的结果表。查询会把 table1 中的每一行与 table2 中的每一行进行比较,找到所有满足连接谓词的行的匹配对。当满足连接谓词时,A 和 B 行的每个匹配对的列值会合并成一个结果行。内连接(INNER JOIN)是最常见的连接类型,是默认的连接类型。INNER 关键字是可选的。
SELECT *
FROM TableA
INNER JOIN TableB
ON TableA.ID = TableB.ID;
ID Name ID Age
1 Alice 1 30
2 Bob 2 25left outer join
首先执行一个内连接。然后,对于表 T1 中不满足表 T2 中连接条件的每一行,其中 T2 的列中有 null 值也会添加一个连接行。因此,连接的表在 T1 中每一行至少有一行
SELECT *
FROM TableA
LEFT OUTER JOIN TableB
ON TableA.ID = TableB.ID;
ID Name ID Age
1 Alice 1 30
2 Bob 2 25
3 Charlie NULL NULLright outer join
首先,执行内部连接。然后,对于表T2中不满足表T1中连接条件的每一行,其中T1列中的值为空也会添加一个连接行。这与左联接相反;对于T2中的每一行,结果表总是有一行。
SELECT *
FROM TableA
RIGHT OUTER JOIN TableB
ON TableA.ID = TableB.ID;
ID Name ID Age
1 Alice 1 30
2 Bob 2 25
NULL NULL 4 40full outer join
执行内部连接。然后,对于表 T1 中不满足表 T2 中任何行连接条件的每一行,如果 T2 的列中有 null 值也会添加一个到结果中。此外,对于 T2 中不满足与 T1 中的任何行连接条件的每一行,将会添加 T1 列中包含 null 值的到结果
SELECT *
FROM TableA
FULL OUTER JOIN TableB
ON TableA.ID = TableB.ID;
ID Name ID Age
1 Alice 1 30
2 Bob 2 25
3 Charlie NULL NULL
NULL NULL 4 40三种算法
在PostgreSQL中,确实有三种主要的连接算法:Nested Loop Join、Merge Join 和 Hash Join。每种算法都有其适用的场景和性能特点。下面是对每种算法的详细解释和示例:
Nested Loop Join
Nested Loop Join 是最简单的连接算法。它通过遍历外表(驱动表)的每一行,然后在内表中查找匹配的行。这种算法适用于小表之间的连接,或者在连接条件上有索引的情况下。
nested loop join: The right relation is scanned once for every row found in the left relation. This strategy is easy to implement but can be very time consuming. (However, if the right relation can be scanned with an index scan, this can be a good strategy. It is possible to use values from the current row of the left relation as keys for the index scan of the right.)
(对于在左关系中找到的每一行,都会对右关系进行一次扫描。这种策略易于实现,但可能非常耗时。不过,如果右关系能够通过索引扫描来进行,那么这可能是一种良好的策略)
示例:
工作原理:
1. 遍历 TableA 的每一行。
2. 对于 TableA 的每一行,遍历 TableB 查找匹配的行。

Merge Join
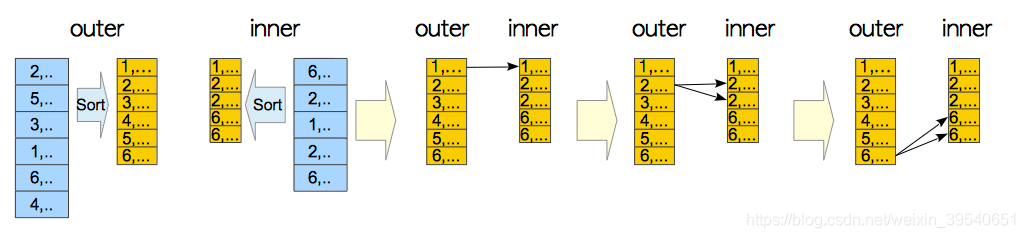
Merge Join 要求两个表在连接列上都有序。它通过同时遍历两个有序的表,找到匹配的行。这种算法适用于大表之间的连接,尤其是在连接列上有索引或数据已经有序的情况下。
示例:
工作原理:
1. 确保 TableA 和 TableB 在连接列上都有序。比如ID是有序的
2. 同时遍历两个有序的表,找到匹配的行。
(“merge join”首先对参与连接的两个关系按照连接属性进行排序处理,使得后续的扫描和匹配操作更加高效。在扫描阶段,两个关系同时进行,一旦发现匹配的行,就将它们组合成连接行。)
Hash Join
Hash Join 通过构建一个哈希表来加速连接操作。它首先遍历外表(驱动表),将其连接列的值哈希化并存储在哈希表中,然后遍历内表,使用相同的哈希函数查找匹配的行。这种算法适用于大表之间的连接,尤其是在内存足够的情况下。
具体hash流程见下面连接对原文的翻译:
(将主驱动表的关联字段作为key,主驱动表需要的字段作为value来构建hash表。
遍历被驱动表的每一行 计算该行是否与hash表中key相同 如果key相同则将被驱动表相应字段和命中hash表key对应的value一起输出,作为结果中的一行。由于hash表的使用,被驱动表的每一行查找时间复杂度为常数)
默认选择较小的表作为构建hash表(见下面的验证截图)
示例:

工作原理:
1. 遍历 TableA,将其连接列的值哈希化并存储在哈希表中。
2. 遍历 TableB,使用相同的哈希函数查找匹配的行。
PostgreSQL 名人 momjian 的文章指出了其pseudo code:
for (j = 0; j < length(inner); j++)
hash_key = hash(inner[j]);
append(hash_store[hash_key], inner[j]);
for (i = 0; i < length(outer); i++)
hash_key = hash(outer[i]);
for (j = 0; j < length(hash_store[hash_key]); j++)
if (outer[i] == hash_store[hash_key][j])
output(outer[i], inner[j]);//利用 inner 表, 来构造 hash 表(放在内存里)
for (j = 0; j < length(inner); j++)
{
hash_key = hash(inner[j]);
append(hash_store[hash_key], inner[j]);
}
//对 outer 表的每一个元素, 进行遍历
for (i = 0; i < length(outer); i++)
{
//拿到 outer 表中的 某个元素, 进行 hash运算, 得到其 hash_key 值
hash_key = hash(outer[i]);
//用上面刚得到的 hash_key值, 来 对 hash 表进行 探测(假定hash表中有此key 值)
//采用 length (hash_store[hash_Key]) 是因为,hash算法构造完hash 表后,有可能出现一个key值处有多个元素的情况。
//例如: hash_key 100 ,对应 a,c, e; 而 hash_key 200 , 对应 d; hash_key 300, 对应 f;
//也就是说, 如下的遍历,其实是对 拥有相同 的 (此处是上面刚运算的,特定的)hash_key 值的各个元素的遍历
for (j = 0; j < length(hash_store[hash_key]); j++)
{
//如果找到了匹配值,则输出一行结果
if (outer[i] == hash_store[hash_key][j])
output(outer[i], inner[j]);
}
}验证


获取原生SQL
from sqlalchemy.dialects import postgres
inf_solution=# explain SELECT project.id, project.name, project.code FROM project JOIN combodemand ON project.id = combodemand.project_id JOIN sub_demand ON combodemand.id = sub_demand.demand_id WHERE sub_demand.vendor_id = 1 GROUP BY project.id;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------
Group (cost=47.55..47.56 rows=1 width=94)
Group Key: project.id
-> Sort (cost=47.55..47.56 rows=1 width=94)
Sort Key: project.id
-> Nested Loop (cost=0.43..47.54 rows=1 width=94)
-> Nested Loop (cost=0.28..47.33 rows=1 width=4)
-> Seq Scan on sub_demand (cost=0.00..39.03 rows=1 width=4)
Filter: (vendor_id = 1)
-> Index Scan using ix_combodemand_id on combodemand (cost=0.28..8.29 rows=1 width=8)
Index Cond: (id = sub_demand.demand_id)
-> Index Scan using ix_project_id on project (cost=0.15..0.21 rows=1 width=94)
Index Cond: (id = combodemand.project_id)
(12 rows)问题
如果inner table 太大不能放到内存中怎么办?
阿里为什么要禁用三表以上的join?
评论区