




读书笔记-智能体上下文工程
感谢🙏阅读和多多**关注**,我会持续输出好的作品🩷
“上下文工程”……实际上是构建人工智能智能体的工程师的首要任务
上下文工程=提示词+用户画像+记忆+检索信息+RAG信息+MCP信息
智能体执行任务需要上下文。上下文工程是一门艺术和科学,即在智能体运行轨迹的每一步,用恰到好处的信息填充上下文窗口
原文地址:Context Engineering for Agents
Agent 上下文工程 - 表单式读书笔记
基本信息
核心概念对照表
发展阶段对比表
挑战与影响分析表
Context Engineering 上下文工程
大语言模型就像是一种新型操作系统。大语言模型就像中央处理器(CPU),其上下文窗口就像随机存取存储器(RAM),充当模型的工作内存。与随机存取存储器一样,大语言模型的上下文窗口处理各种上下文来源的能力也有限。就像操作系统会管理适合放入中央处理器随机存取存储器的内容一样,“上下文工程”也起着类似的作用。
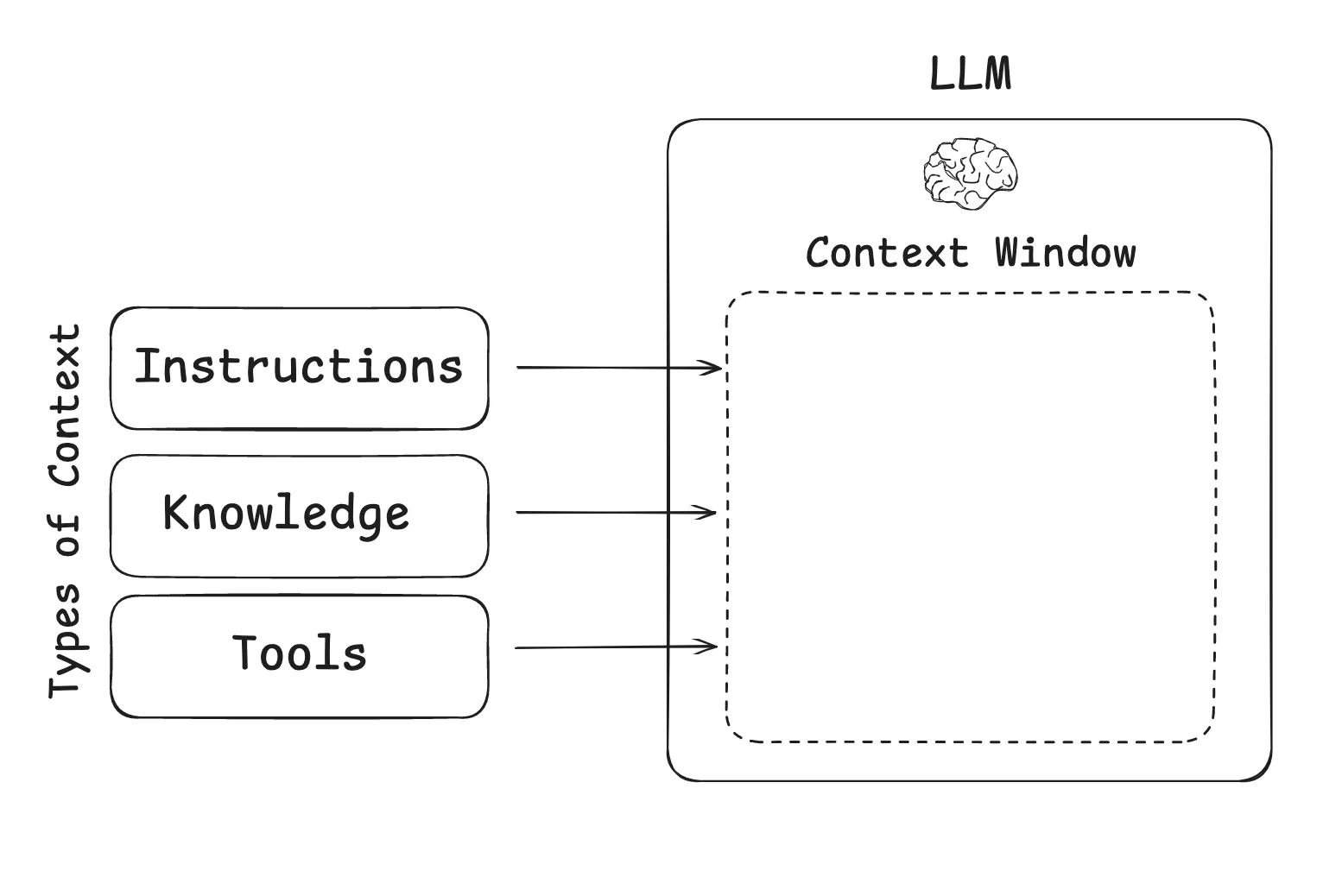
在构建大语言模型(LLM)应用程序时,我们需要管理哪些类型的上下文?上下文工程是一个涵盖多种不同上下文类型的统称:
指令+知识+工具
1
Instructions – prompts, memories, few‑shot examples, tool descriptions, etc(指令——提示词、记忆、少样本示例、工具描述等)
2
Knowledge – facts, memories,( etc 知识——事实、记忆等)
3
Tools – feedback from tool calls 工具 - (来自工具调用的反馈)
智能体上下文工程
大语言模型(LLMs)在推理和工具调用方面的能力不断提升,人们对智能体的兴趣大幅增长。智能体将大语言模型调用与工具调用穿插进行,通常用于长时间运行的任务。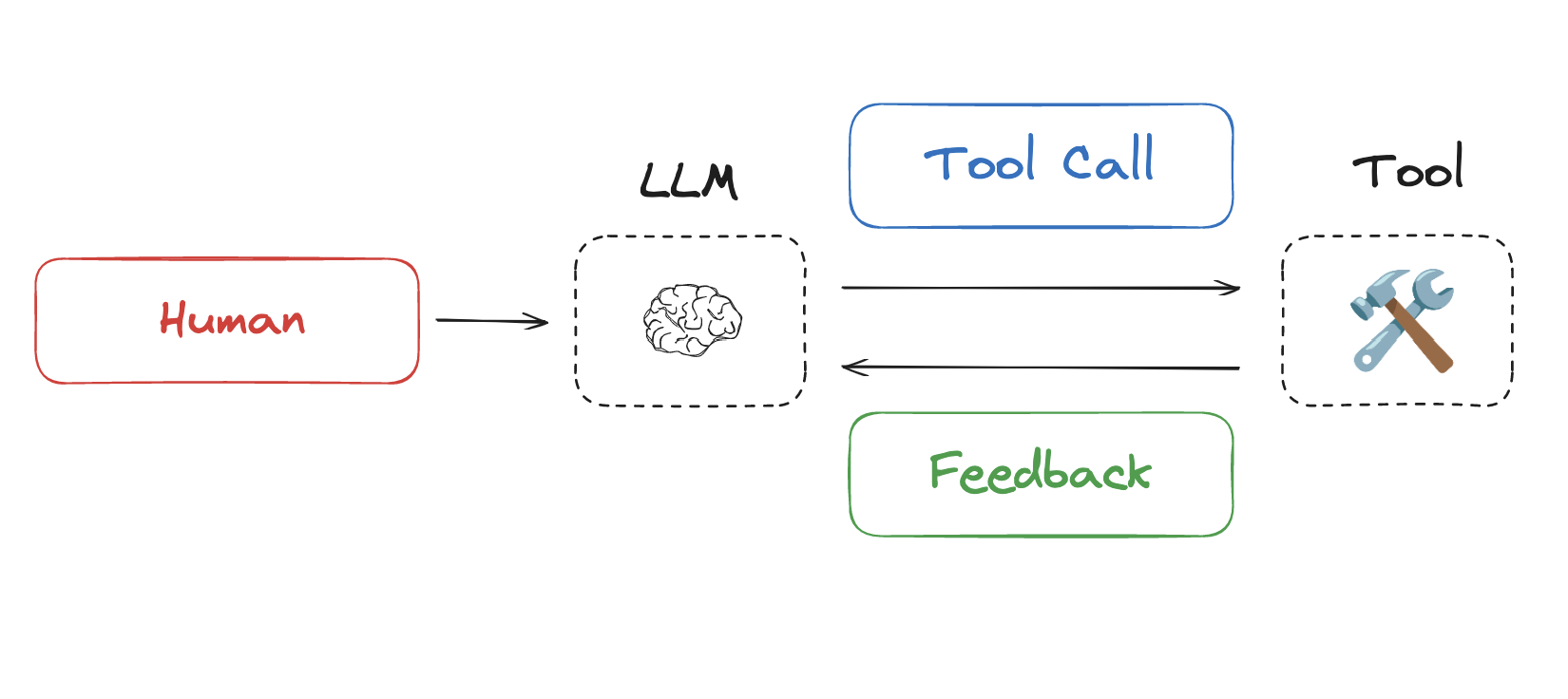
缺陷:长时间运行的任务以及工具调用不断积累的反馈意味着智能体经常会使用大量的令牌,导致“超出上下文窗口的大小,使成本/延迟大幅增加,或者降低智能体的性能”:
1
Context Poisoning: When a hallucination makes it into the context 上下文中毒:当幻觉混入上下文时
2
Context Distraction: When the context overwhelms the training 上下文干扰:当上下文信息超出训练范围时
3
Context Confusion: When superfluous context influences the response 上下文混淆:当多余的上下文影响回复时
4
Context Clash: When parts of the context disagree 上下文冲突:当上下文的各个部分不一致时
四类解决方法
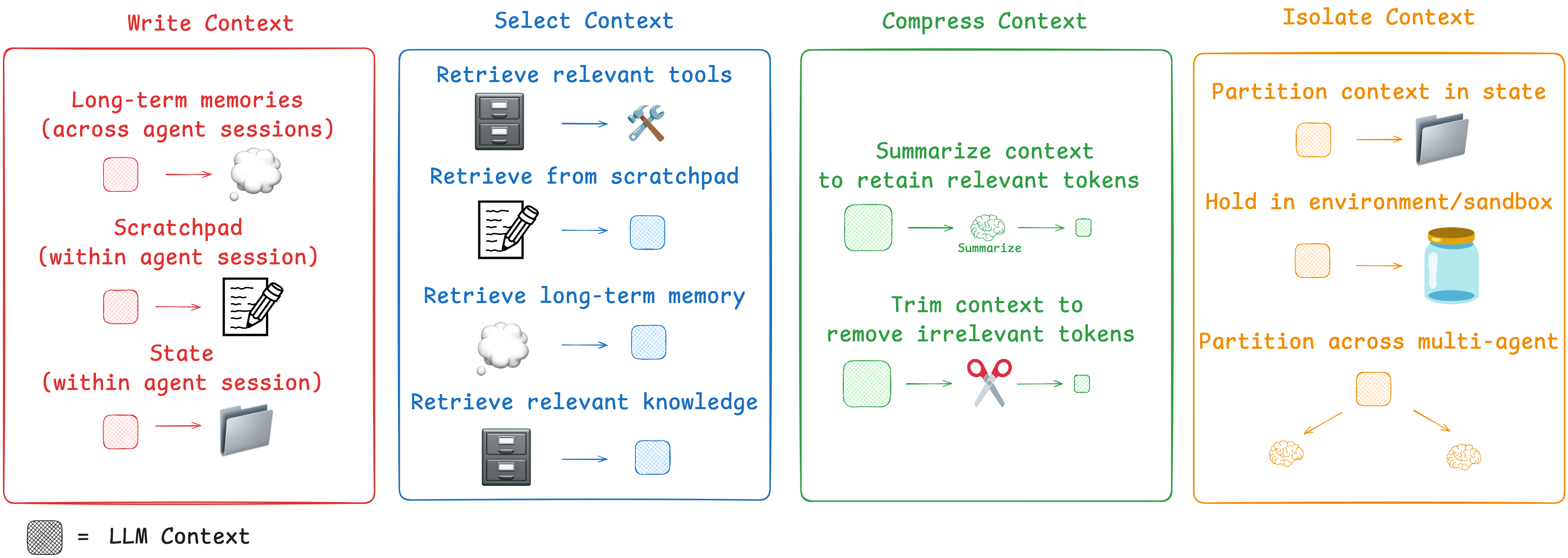
“编写、选择、压缩和隔离”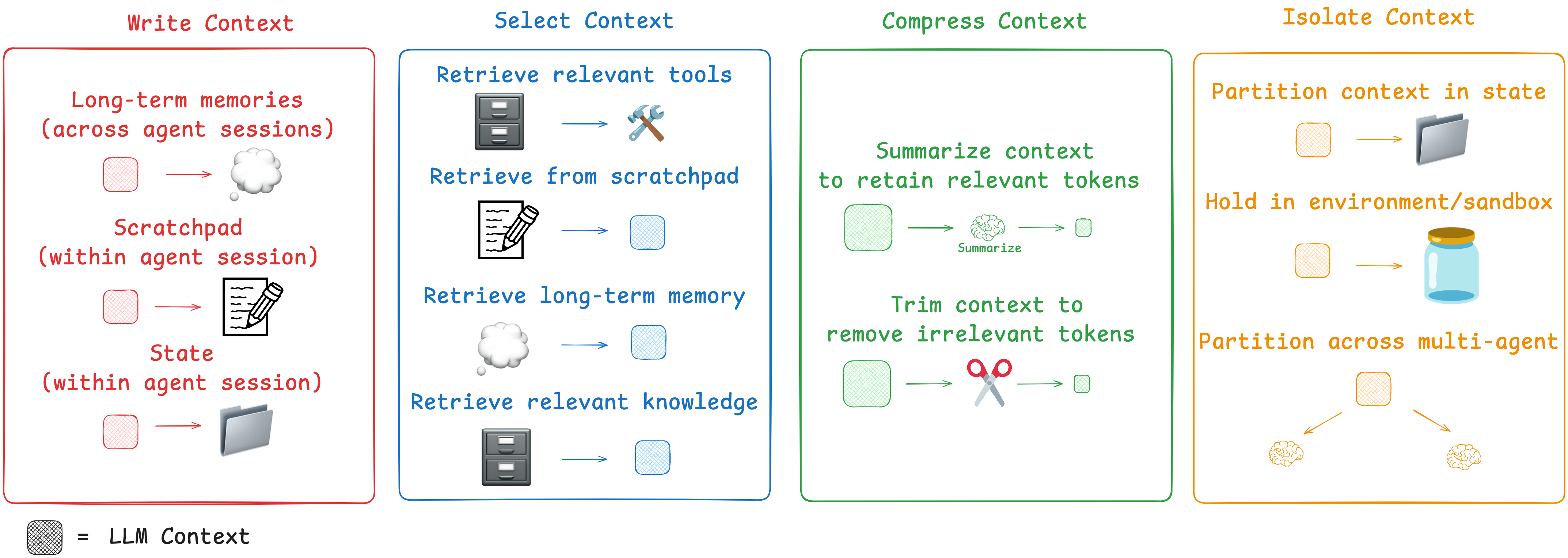
Write Context 编写上下文
“写入上下文是指将其保存在上下文窗口之外,以帮助智能体执行任务。”
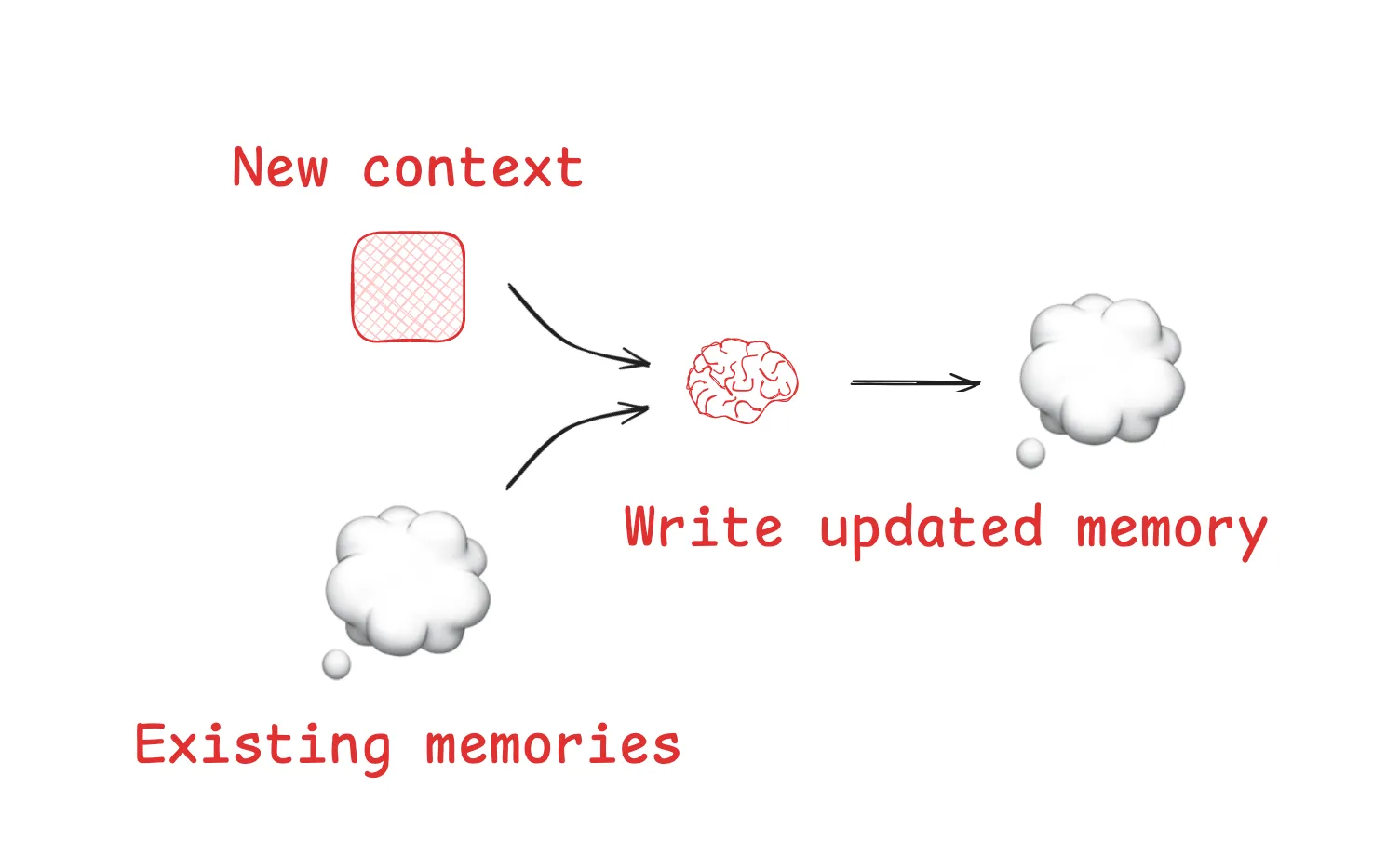
暂存区
当人类解决任务时,我们会做笔记,并记住相关信息以便未来处理相关任务。智能体也在获得这些能力!在智能体执行任务时,通过 “暂存区” 做笔记是一种保存信息的方法。其核心思想是在上下文窗口之外保存信息,以便智能体能够获取:它们可以是一种工具调用,简单地写入文件。它也可以只是运行时状态对象中的一个字段,在会话期间持续存在。无论哪种情况,暂存区都能让智能体保存有用信息,以帮助它们完成任务。
记忆
暂存区帮助智能体在给定的会话中解决任务,但有时智能体也会从跨多个会话记住信息中受益。Reflexion提出了在每次智能体行动后进行反思并重新利用这些自我生成的记忆的想法。生成式智能体根据过去智能体反馈的集合定期合成记忆。使得产品都具备基于用户与智能体交互自动生成长期记忆的机制。
上下文选择
“选择上下文意味着将其拉入上下文窗口,以帮助智能体执行任务”
Scratchpad 草稿区
从暂存区选择上下文的机制取决于暂存区的实现方式。如果它是一个工具,那么智能体可以通过调用工具来读取它。如果它是智能体运行时状态的一部分,那么开发人员可以选择在每一步向智能体暴露状态的哪些部分。这为在后续轮次中向大语言模型(LLM)暴露暂存区上下文提供了细粒度的控制
记忆
如果智能体具备保存记忆的能力,那么它们也需要具备选择与当前执行任务相关记忆的能力。这出于以下几个原因:智能体可能会选择少样本示例(情景记忆),以获取期望行为的示例;选择指令(程序记忆)来引导行为;或者选择事实(语义记忆),从而为智能体提供与任务相关的背景信息。
工具
见下文
知识
检索增强生成(RAG)是一个丰富的主题,可能是核心的上下文工程挑战。代码智能体是大规模生产中检索增强生成(RAG)的一些最佳示例
压缩上下文
保留任务执行所需的词元
Context Summarization 上下文总结
智能体交互可能会历经数百轮,并使用消耗大量令牌的工具调用。摘要生成是应对这些挑战的一种常见方法。如果你使用过Claude Code,就会看到它的实际应用。当你超过上下文窗口的95%时,Claude Code会运行“自动压缩”,它将总结用户与智能体交互的完整轨迹。这种跨智能体轨迹的压缩可以采用各种策略,如递归或分层摘要生成。
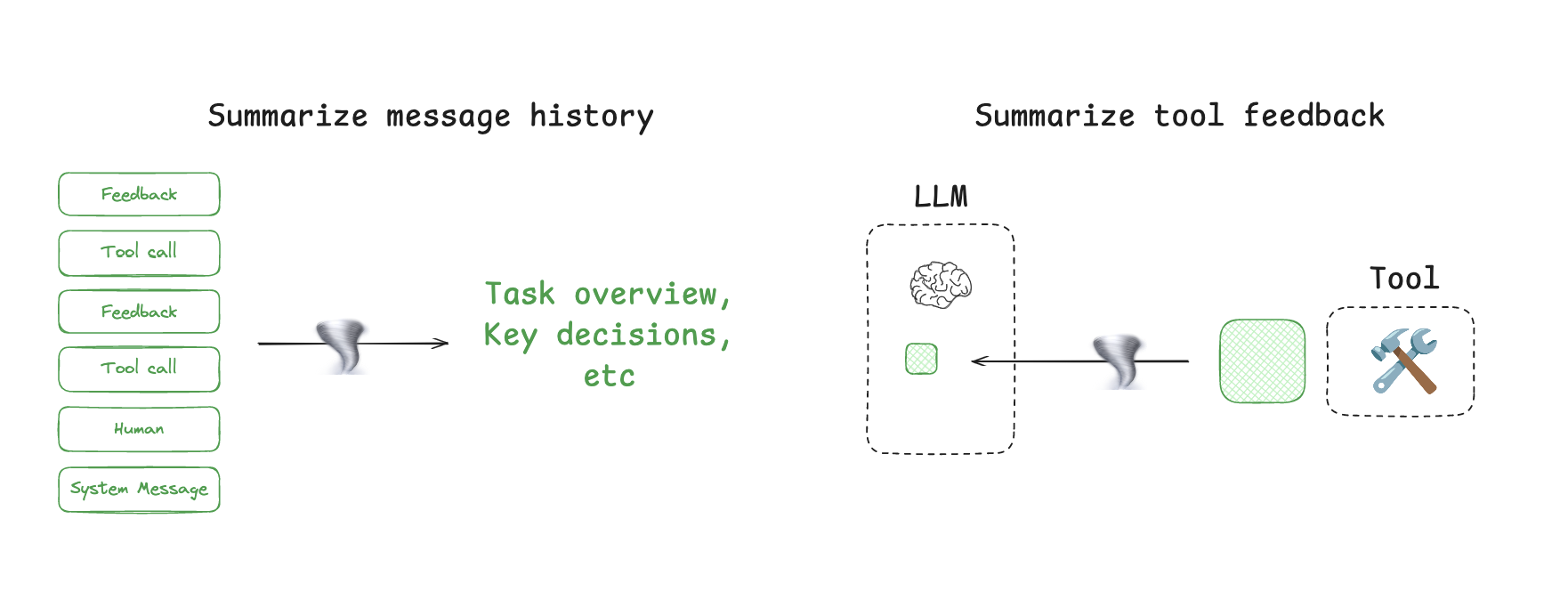
Context Trimming 上下文修剪
对上下文修建整理
Isolating Context 隔离上下文
“隔离上下文涉及将其拆分,以帮助智能体执行任务”
多智能体
隔离上下文最常用的方法之一是将其分配给多个子智能体。OpenAI的Swarm库的设计初衷是实现“关注点分离”,即由一组智能体来处理子任务。每个智能体都有一套特定的工具、指令和自己的上下文窗口。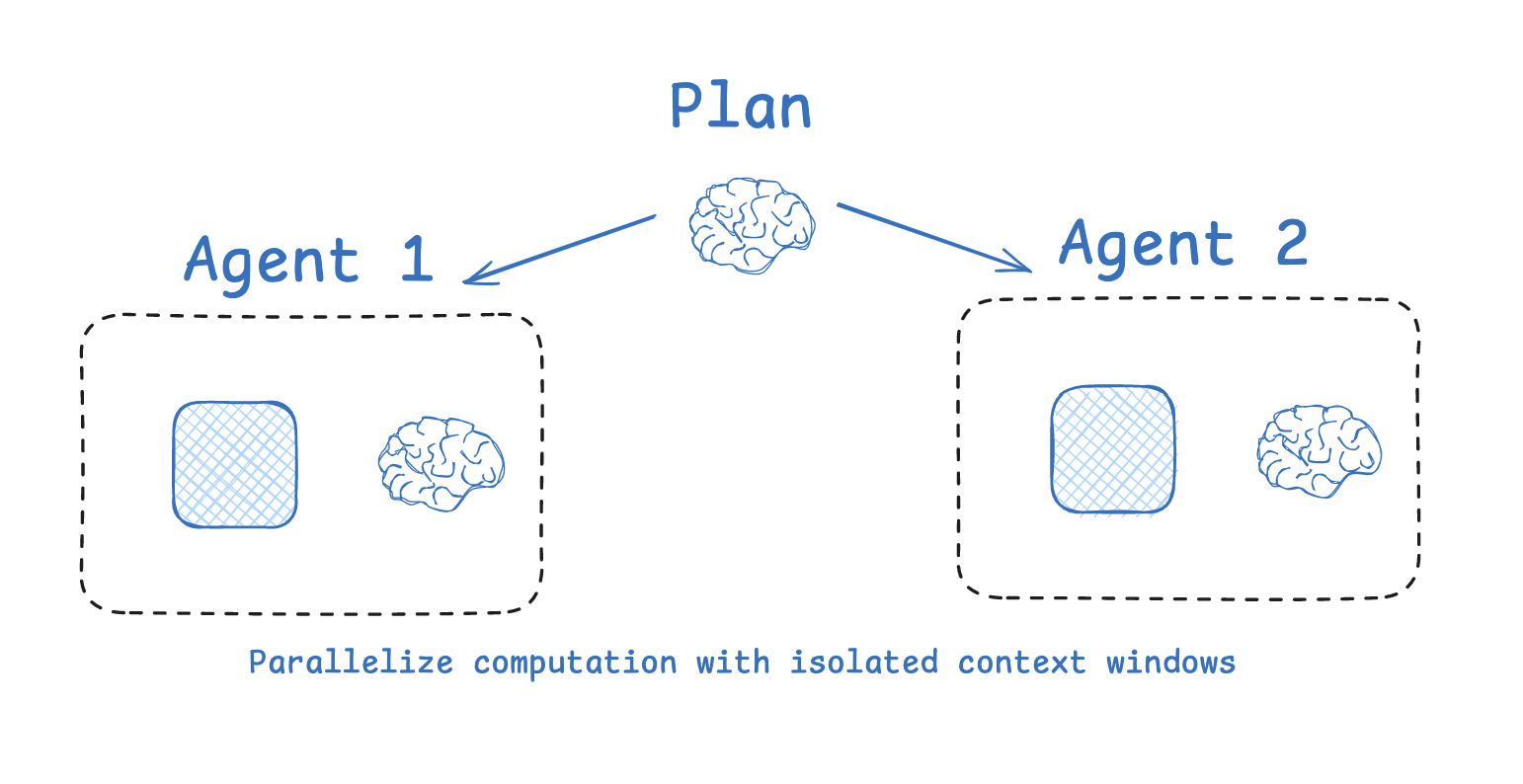
“许多具有独立上下文的智能体的表现优于单智能体,这在很大程度上是因为每个子智能体的上下文窗口可以分配给更具体的子任务。”
总结
1
Writing context means saving it outside the context window to help an agent perform a task.写入上下文是指将其保存在上下文窗口之外,以帮助智能体执行任务。
2
Selecting context means pulling it into the context window to help an agent perform a task.选择上下文意味着将其拉入上下文窗口,以帮助智能体执行任务。
3
Compressing context involves retaining only the tokens required to perform a task.压缩上下文涉及只保留执行任务所需的词元。
4
Isolating context involves splitting it up to help an agent perform a task.隔离上下文涉及将其拆分,以帮助智能体执行任务。
评论区