




术语
Raft:etcd所采用的保证分布式系统强一致性的算法。
Node:一个Raft状态机实例。
Member:一个etcd实例。它管理着一个Node,并且可以为客户端请求提供服务。
Cluster:由多个Member构成可以协同工作的etcd集群。
Peer:对同一个etcd集群中另外一个Member的称呼。
Client:向etcd集群发送HTTP请求的客户端。
WAL:预写式日志,etcd用于持久化存储的日志格式。
snapshot:etcd防止WAL文件过多而设置的快照,存储etcd数据状态。
Proxy:etcd的一种模式,为etcd集群提供反向代理服务。
Leader:Raft算法中通过竞选而产生的处理所有数据提交的节点。
Follower:竞选失败的节点作为Raft中的从属节点,为算法提供强一致性保证。
Candidate:当Follower超过一定时间接收不到Leader的心跳时转变为Candidate开始竞选。
Term:某个节点成为Leader到下一次竞选时间,称为一个Term。
Index:数据项编号。Raft中通过Term和Index来定位数据。
架构
1. etcd 项目结构和功能
etcd 项目代码的目录结构如下:
$ tree
├── auth
├── build
├── client
├── clientv3
├── contrib
├── embed
├── etcdctl
├── etcdmain
├── etcdserver
├── functional
├── hack
├── integration
├── lease
├── logos
├── mvcc
├── pkg
├── proxy
├── raft
├── scripts
├── security
├── tests
├── tools
├── vendor
├── version
└── wal
每个模块的功能如下:
etcd 核心的模块有 lease、mvcc、raft、etcdserver,其余都是辅助的功能。其中 etcdserver 是其他模块的整合。
2. etcd 整体架构
etcd 整体架构图如下:
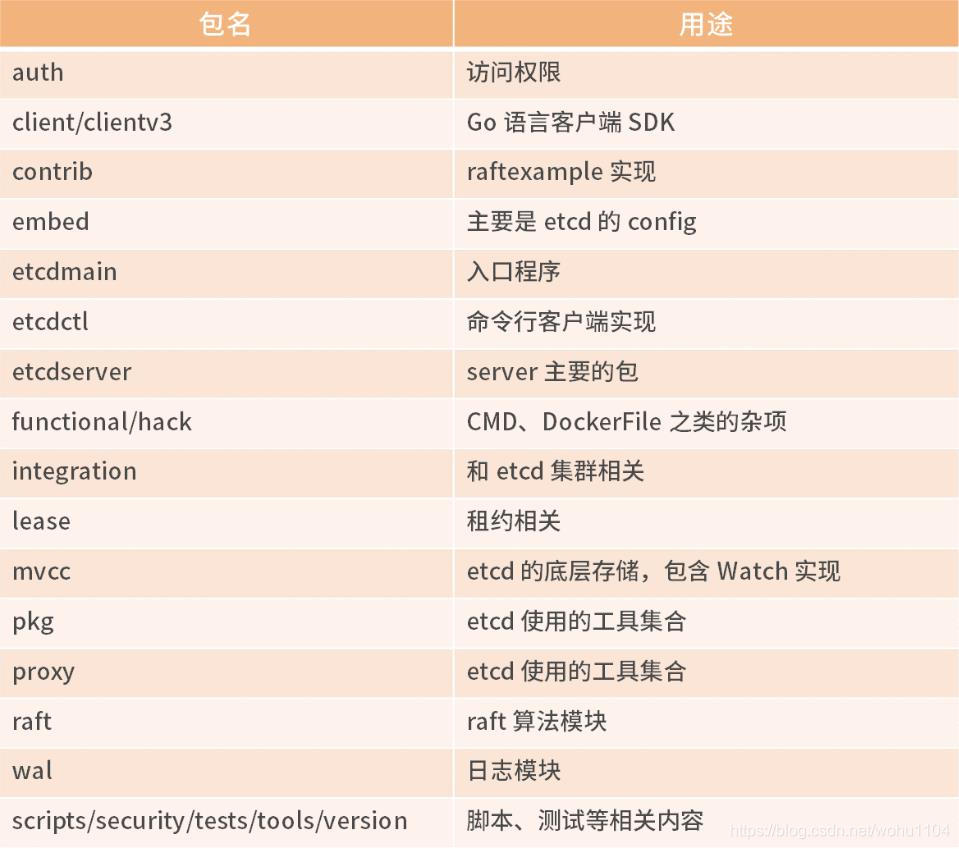
2.1 客户端层 包括 clientv3 和 etcdctl 等客户端。用户通过命令行或者客户端调用提供了 RESTful 风格的 API,降低了 etcd 的使用复杂度。
除此之外,客户端层的负载均衡(etcd V3.4 版本的客户端默认使用的是 Round-robin,即轮询调度)和节点间故障转移等特性,提升了 etcd 服务端的高可用性。需要注意的是,etcd V3.4 之前版本的客户端存在负载均衡的 Bug,如果第一个节点出现异常,访问服务端时也可能会出现异常,建议进行升级。
2.2 API 接口层 API 接口层提供了客户端访问服务端的通信协议和接口定义,以及服务端节点之间相互通信的协议。
etcd 有 V3 和 V2 两个版本。
etcd V3 使用 gRPC 作为消息传输协议; etcd V2 默认使用 HTTP/1.x 协议。 对于不支持 gRPC 的客户端语言,etcd 提供 JSON 的 grpc-gateway 。通过 grpc-gateway 提供 RESTful代理,转换 HTTP/JSON 请求为 gRPC 的 Protocol Buffer 格式的消息。
2.3 etcd Raft 层 负责 Leader 选举和日志复制等功能,除了与本节点的 etcd Server 通信之外,还与集群中的其他 etcd 节点进行交互,实现分布式一致性数据同步的关键工作。
2.4 逻辑层 etcd 的业务逻辑层,包括鉴权、租约、KVServer、MVCC 和 Compactor 压缩等核心功能特性。
2.5 etcd 存储 实现了快照、预写式日志 WAL(Write Ahead Log)。etcd V3 版本中,使用 BoltDB 来持久化存储集群元数据和用户写入的数据。
模块交互
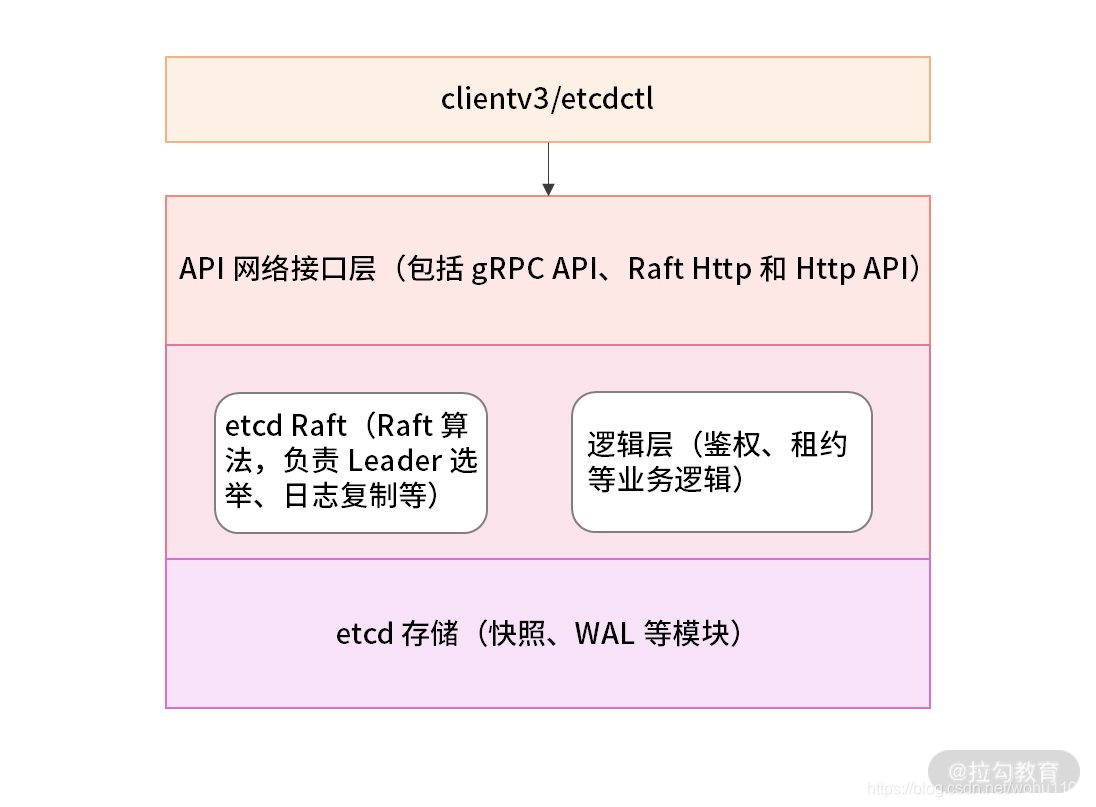
- 各个模块之间的交互 下图中展示了 etcd 处理一个客户端请求涉及的模块和流程。
从上至下依次为 客户端 → API 接口层 → etcd Server → etcd raft 算法库。我们根据请求处理的过程,将 etcd Server 和 etcd raft 算法库单独说明。
3.1 etcd Server 接收客户端的请求,在上述的 etcd 项目代码中对应 etcdserver 包。请求到达 etcd Server 之后,经过 KVServer 拦截,实现诸如日志、Metrics 监控、请求校验等功能。 etcd Server 中的 raft 模块,用于与 etcd-raft 库进行通信。
applierV3 模块封装了 etcd V3 版本的数据存储;WAL 用于写数据日志,WAL 中保存了任期号、投票信息、已提交索引、提案内容等,etcd 根据 WAL 中的内容在启动时恢复,以此实现集群的数据一致性。
3.2 etcdraft etcd 的 raft 库。raftLog 用于管理 raft 协议中单个节点的日志,都处于内存中。
raftLog 中还有两种结构体 unstable 和 storage,这两种结构体分别用于不同步骤的存储,区别如下
unsable 中存储不稳定的数据,表示还没有 commit;storage 中都是已经被 commit 了的数据; 除此之外,raft 库更重要的是负责与集群中的其他 etcd Server 进行交互,实现分布式一致性。
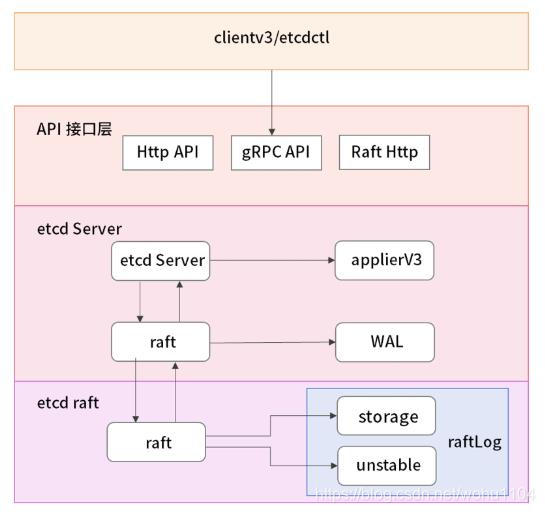
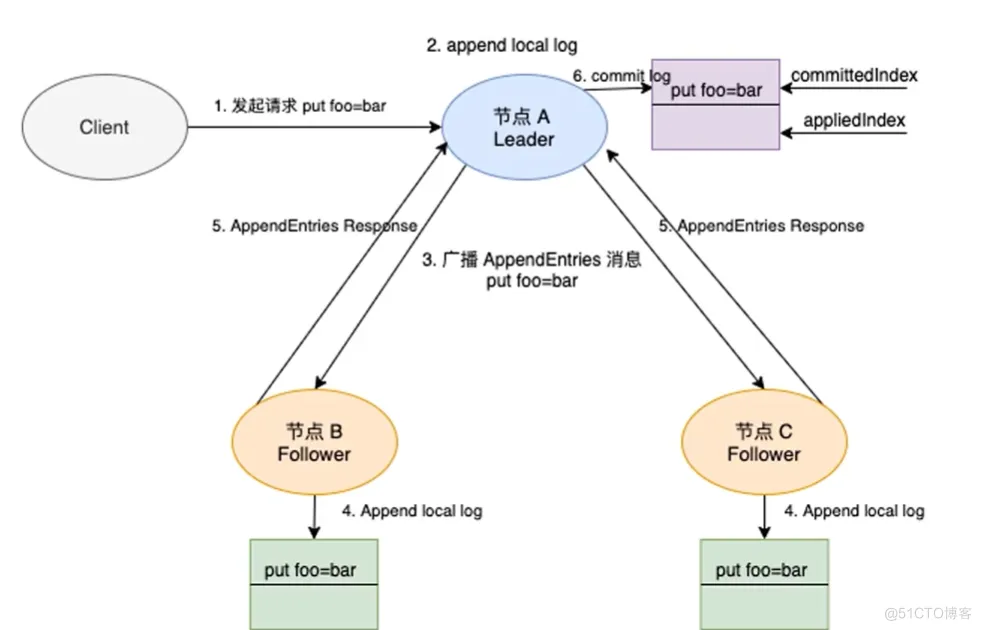
3.3 交互细节 在上图中,客户端请求与 etcd 集群交互包括如下两个步骤:
首先是写数据到 etcd 节点中;
其次是当前的 etcd 节点与集群中的其他 etcd 节点之间进行通信,确认存储数据成功之后回复客户端;
请求流程可划分为以下的子步骤:
客户端通过负载均衡算法选择一个 etcd 节点,发起 gRPC 调用;
etcd Server 收到客户端请求;
经过 gRPC 拦截、Quota 校验,Quota 模块用于校验 etcd db 文件大小是否超过了配额;
接着 KVServer 模块将请求发送给本模块中的 raft,这里负责与 etcd raft 模块进行通信;
发起一个提案,命令为 put foo bar,即使用 put 方法将 foo 更新为 bar;
在 raft 中会将数据封装成 raft 日志的形式提交给 raft 模块;
raft 模块会首先保存到 raftLog 的 unstable 存储部分;
raft 模块通过 raft 协议与集群中其他 etcd 节点进行交互。
需要注意的是,在 raft 协议中写入数据的 etcd 必定是 leader 节点,如果客户端提交数据到非 leader 节点时,该节点需要将请求转发到 etcd leader 节点处理。
响应流程的步骤如下:
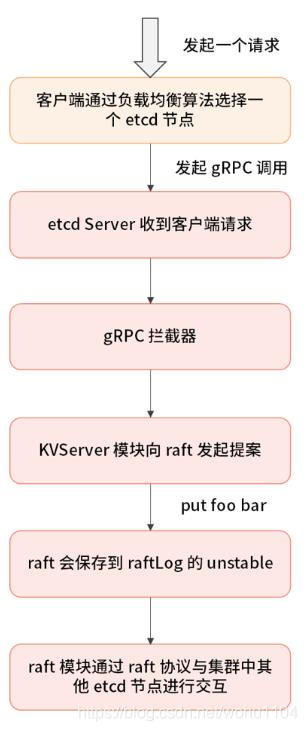
提案通过 RaftHTTP 网络模块转发,集群中的其他节点接收到该提案;
在收到提案之后,集群中其他节点向 leader 节点应答“我已经接收这条日志数据”;
Leader 收到应答之后,统计应答的数量,当满足超过集群半数以上节点,应答接收成功;
etcd raft 算法模块构造 Ready 结构体,用来通知 etcd Server 模块,该日志数据已经被 commit;
etcd Server 中的 raft 模块(交互图中有标识),收到 Ready 消息后,会将这条日志数据写入到 WAL 模块中;
正式通知 etcd Server 该提案已经被 commit;
etcd Server 调用 applierV3 模块,将日志写入持久化存储中;
etcd Server 应答客户端该数据写入成功;
etcd Server 调用 etcd raft 库,将这条日志写入到 raftLog 模块中的 storage;
上述过程中,提案经过网络转发,当多数 etcd 节点持久化日志数据成功并进行应答,提案的状态会变成已提交。
在应答某条日志数据是否已经 commit 时,为什么 etcd raft 模块首先写入到 WAL 模块中?
这是因为该过程仅仅添加一条日志,一方面开销小,速度会很快;另一方面,如果在后面 applierV3 写入失败,etcd 服务端在重启的时候也可以根据 WAL 模块中的日志数据进行恢复。etcd Server 从 raft 模块获取已提交的日志条目,由 applierV3 模块通过 MVCC 模块执行提案内容,更新状态机。
整个过程中,etcd raft 模块中的 raftLog 数据在内存中存储,在服务重启后失效;客户端请求的数据则被持久化保存到 WAL 和 applierV3 中,不会在重启之后丢失。
数据读写
为了保证数据的强一致性,etcd集群中所有的数据流向都是一个方向,从 Leader (主节点)流向 Follower,也就是所有 Follower 的数据必须与 Leader 保持一致,如果不一致会被覆盖。
用户对于etcd集群所有节点进行读写
读取:由于集群所有节点数据是强一致性的,读取可以从集群中随便哪个节点进行读取数据
写入:etcd集群有leader,如果写入往leader写入,可以直接写入,然后然后Leader节点会把写入分发给所有Follower,如果往follower写入,然后Leader节点会把写入分发给所有Follower etcd认为写入请求被Leader节点处理并分发给了多数节点后,就是一个成功的写入。那么多少节点如何判定呢,假设总结点数是N,那么多数节点
Quorum=N/2+1。关于如何确定etcd集群应该有多少个节点的问题,上图的左侧的图表给出了集群中节点总数(Instances)对应的Quorum数量,用Instances减去Quorom就是集群中容错节点(允许出故障的节点)的数量。
所以在集群中推荐的最少节点数量是3个,因为1和2个节点的容错节点数都是0,一旦有一个节点宕掉整个集群就不能正常工作了
只考虑log entries的话,unstable是未落盘的,WAL是已落盘entries,storage是访问已落盘数据的interface,具体实现上,一般是WAL加某种cache的实现。etcd自带的memoryStorage实现这个storage接口,但比较简单,是没有被compact掉的已落盘entries在内存的一份拷贝,和传统意义cache不同,因为它有已落盘未compact掉的所有数据。unstable不是复制数据的来源,在有follower落后、刚重启、新join的情况下,给这类follower的数据多数来自已落盘部分。cockroachdb使用一个基于llrb的LRU cache来替代memoryStorage这个东西,WAL部分是rocksdb
评论区