




python——GC机制
https://blog.51cto.com/u_14666251/4674779
https://zhuanlan.zhihu.com/p/83251959
1. 什么是python垃圾
当我们的Python解释器在执行到定义变量的语法时,会申请内存空间来存放变量的值,而内存的容量是有限的,这就涉及到变量值所占用内存空间的回收问题。
当一个对象或者说变量没有用了,就会被当做“垃圾“。
2. 内存泄漏&内存溢出
内存溢出:程序在申请内存时,没有足够的内存空间供其使用,出现 out of memory
内存泄露:程序在申请内存后,无法释放已申请的内存空间,一次内存泄露危害可以忽略,但内存泄露堆积后果很严重,无论多少内存,迟早会被占光。
2.1 内存泄漏场景&排查
2.1.1 内存泄漏几种场景
1. 没有开gc,或者gc设为debug状态,导致交叉引用没有被回收调
2. 如果一个数据在逻辑上不应该存在,但是因为代码上没有做相关清除操作,导致他还存在,也是一种泄漏;
举个栗子,例如我要记录最近50天的某个基金的日化收益率,定义一个全局的字典global_dict,运行了一个脚本进行计算,没10分钟算一次,但是我没有进行clear操作,每次的计算只是单纯的赋值dict[date] = rate,按理来说dict["五十天前"]的收益率都是不需要的,就是一种泄漏。
3. 这种情况出现在python3.4之前,因为3.4已经修复了,是这样的,如果一个类定义了__del__,并且该类存在循环引用的情况,这时候gc就会把这个类放在gc.garbage当中,不会去做回收,可以说是跳出了分代回收的机制,但是3.4之后的版本就没有这种情况,会把他回收调。
2.1.2 内存泄漏排查
1. 如果是第一种情况解决就最简单了,可以用某个调试库连接到线上的进程,这里推荐pyrasite,但是要注意,这东西很久都没有更新了,所以有可能会和py的版本出现不相容的情况,例如python3.6就把itervalues改为values,导致一些工具用不到,不过没关系,我们只是用它来连上去,看gc而且,等我们连上进程后,就可以调用gc.isenable()去看gc有没有打开了或者状态是否正确
2. 第二种情况就比较复杂了,我建议线下压测复现,不管是rpc还是一般的web服务,我相信写压测脚本都不难。
这里我推荐一个库,objgraph,这个库是基于gc的,他带有以下几个功能。
● show_growth(limit = n),这个函数的作用就是距离上一次这个函数调用之后,那几个类型增长得最多,显示前n个。
● show_backrefs()/show_backrefs(),这个函数的作用就是找出某个object的引用链。
去看那些类型增长异常,首先这些类型一般是我们自定义的类型,不太可能是基础类型。找到异常类型之后,我们就可以调用函数去找出这个类型的引用链,重而确定bug。
3. 第三种情况,有可能在第二种情况下找出来,我们的解决方法可以是把python版本进行一个升级,或者做相关的修改。
3. 引用计数法
3.1 引用计数法介绍
python内部通过引用计数机制来统计一个对象被引用的次数。当这个数变成0的时候,就说明这个对象没有被引用了。这个时候它就变成了“垃圾”。
这个引用计数又是何方神圣呢?让我们看看代码
text = "hello,world"上面的一行代码做了哪些工作呢?
● 创建字符串对象:它的值是hello,world,
● 开辟内存空间:在对象进行实例化的时候,解释器会为对象分配一段内存地址空间。把这个对象的结构体存储在这段内存地址空间中。
我们再来看看这个对象的结构体
typedef struct_object {
int ob_refcnt;
struct_typeobject *ob_type;
} PyObject;
熟悉c语言或者c++的朋友,看到这个应该特别熟悉,他就是结构体。这是因为我们Python官方的解释器是CPython,它底层调用了很多的c类库与接口。所以一些底层的数据是通过结构体进行存储的。看不懂的朋友也没有关系。
这里,我们只需要关注一个参数:ob_refcnt
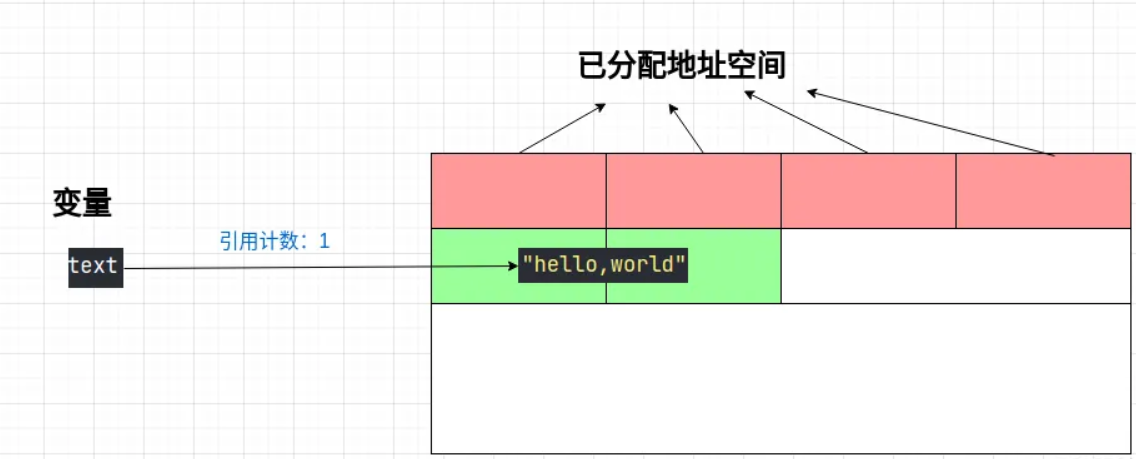
这个参数非常神奇,它记录了这个对象的被变量引用的次数。所以上面 hello,world 这个对象的引用计数就是 1,因为现在只有text这个变量引用了它。
①变量初始化赋值:
text = "hello,world"
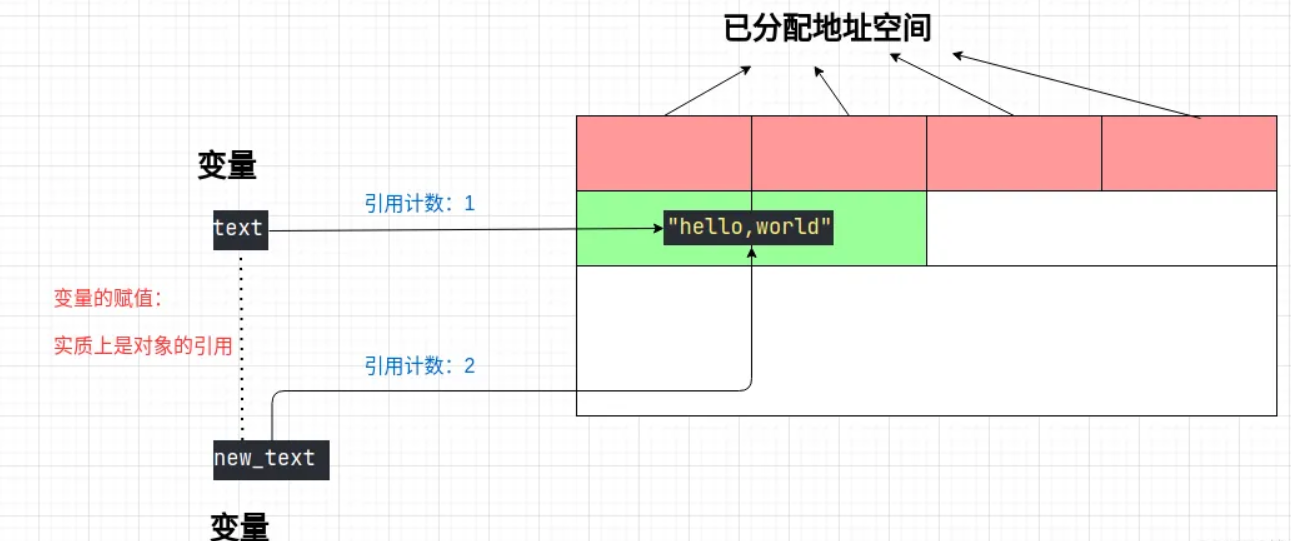
②变量引用传递:
new_text = text
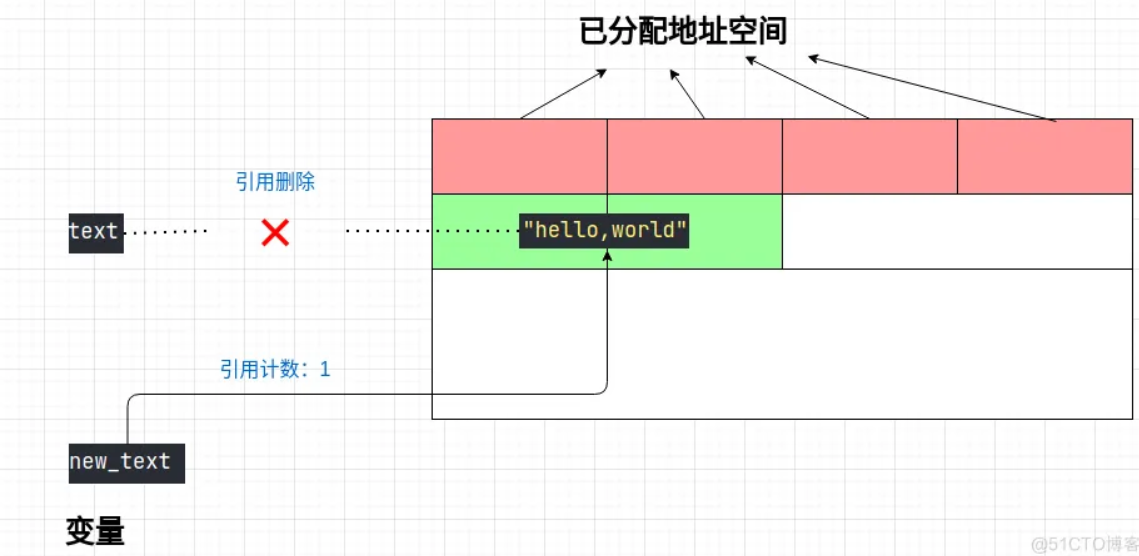
③删除第一个变量:
del text
④删除第二个变量:
del new_text
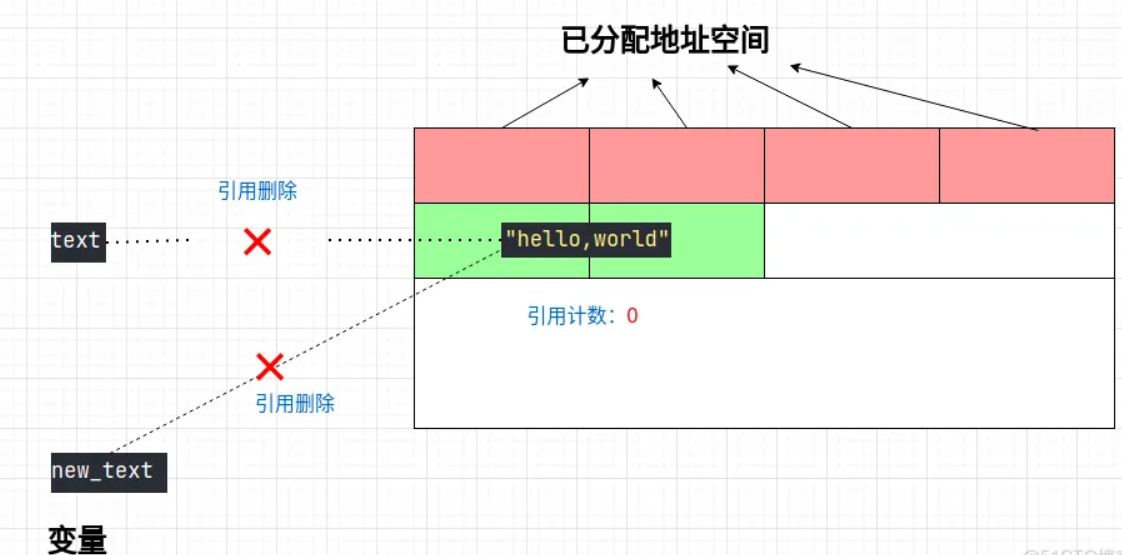
此时 “hello,world” 对象的引用计数为:0,被当成了垃圾。下一步,就该被我们的垃圾回收器给收走了。
3.2 引用计数+1
● 对象被创建
● 对象被别的变量引用(赋值给一个变量)
● 对象被作为元素,放在容器中(比如被当作元素放在列表中)
● 对象作为参数传递给函数
a = "hello,world"
b = a
list = []
list.append(a)
func(a)3.3 引用计数-1
● 对象的引用变量被显示销毁
● 对象的引用变量赋值引用其他对象
● 对象从容器中被移除,或者容器被销毁(例:对象从列表中被移除,或者列表被销毁)
● 一个引用离开了它的作用域
del a
a = "hello, Python" # a的原来的引用对象:a = "hello,world"
del list
list.remove(a)
func():
a = "hello,world"
return
func() # 函数执行结束以后,函数作用域里面的局部变量a会被释放
3.4 引用计数查看
如果要查看对象的引用计数,可以通过内置模块 sys 提供的 getrefcount 方法去查看。
import sys
a = "hello,world"
print(sys.getrefcount(a))
注意:当使用某个引用作为参数,传递给 getrefcount() 时,参数实际上创建了一个临时的引用。因此,getrefcount() 所得到的结果,会比期望的多 1
3.5 引用技术优缺点
引用计数法有其明显的优点,如高效、实现逻辑简单、具备实时性,一旦一个对象的引用计数归零,内存就直接释放了。不用像其他机制等到特定时机。将垃圾回收随机分配到运行的阶段,处理回收内存的时间分摊到了平时,正常程序的运行比较平稳。
但是,引用计数也存在着一些缺点,通常的缺点有:
● 逻辑简单,但实现有些麻烦。每个对象需要分配单独的空间来统计引用计数,这无形中加大的空间的负担,并且需要对引用计数进行维护,在维护的时候很容易会出错。
● 在一些场景下,可能会比较慢。正常来说垃圾回收会比较平稳运行,但是当需要释放一个大的对象时,比如字典,需要对引用的所有对象循环嵌套调用,从而可能会花费比较长的时间。
● 循环引用。这将是引用计数的致命伤,引用计数对此是无解的,因此必须要使用其它的垃圾回收算法对其进行补充。
4. 垃圾回收机制
Python的GC模块主要运用了“引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题,并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
4.1 标记-清除策略
Python采用了标记-清除策略,解决容器对象可能产生的循环引用问题。
该策略在进行垃圾回收时分成了两步,分别是:
● 标记阶段,遍历所有的对象,如果是可达的(reachable),也就是还有对象引用它,那么就标记该对象为可达;
● 清除阶段,再次遍历对象,如果发现某个对象没有标记为可达,则就将其回收
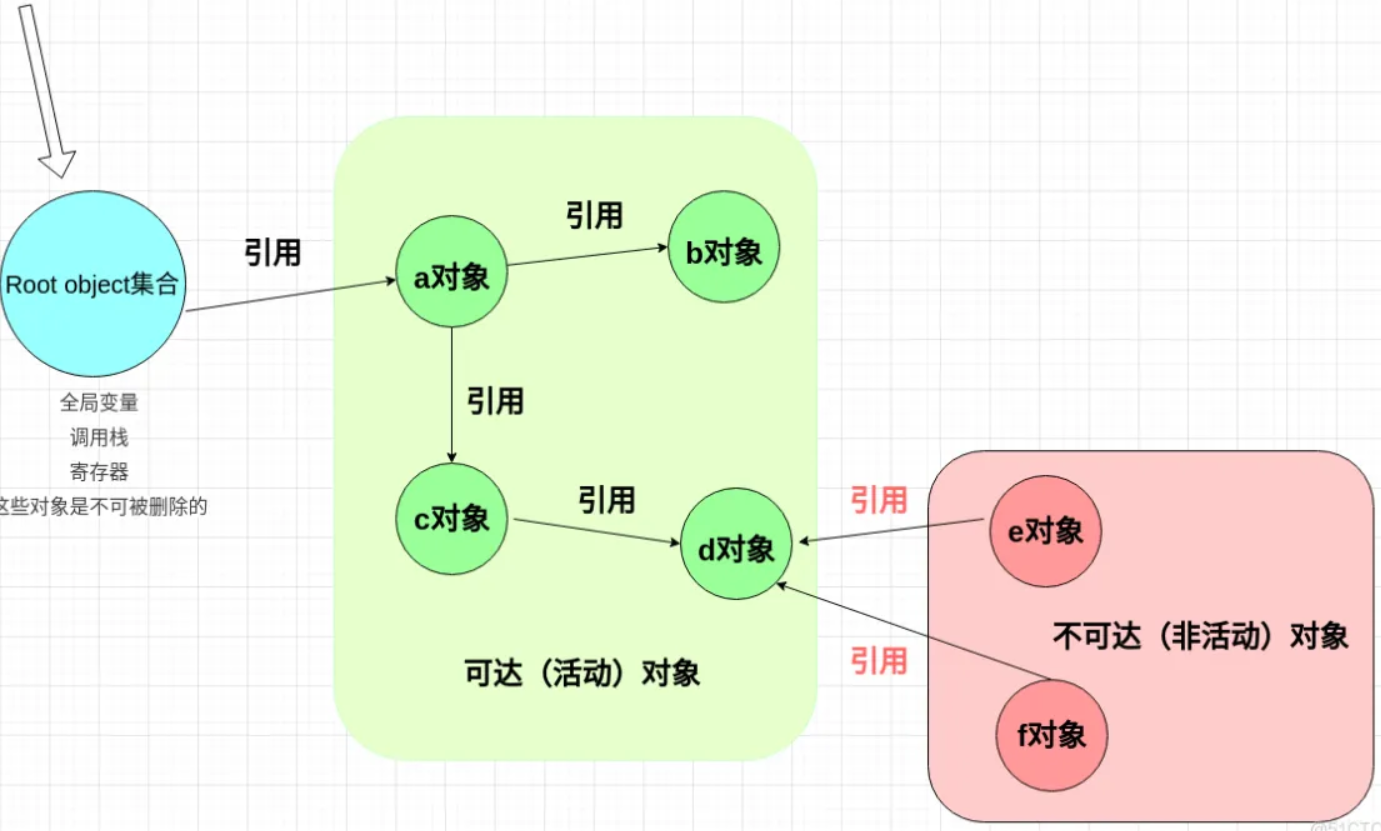
可达(活动)对象:从root集合节点有(通过链式引用)路径达到的对象节点
不可达(非活动)对象:从root集合节点没有(通过链式引用)路径到达的对象节点
流程:
1. 首先,从root集合节点出发,沿着有向边遍历所有的对象节点
2. 对每个对象分别标记可达对象还是不可达对象
3. 再次遍历所有节点,对所有标记为不可达的对象进行垃圾回收、销毁。
4.1.1 标记-清除实现机制
在标记清除算法中,为了追踪容器对象,需要每个容器对象维护两个额外的指针,用来将容器对象组成一个双端链表,指针分别指向前后两个容器对象,方便插入和删除操作。python解释器(Cpython)维护了两个这样的双端链表,一个链表存放着需要被扫描的容器对象,另一个链表存放着临时不可达对象。在图中,这两个链表分别被命名为”Object to Scan”和”Unreachable”。
图中例子是这么一个情况:link1,link2,link3组成了一个引用环,同时link1还被一个变量A(其实这里称为名称A更好)引用。link4自引用,也构成了一个引用环。从图中我们还可以看到,每一个节点除了有一个记录当前引用计数的变量ref_count还有一个gc_ref变量,这个gc_ref是ref_count的一个副本,所以初始值为ref_count的大小。
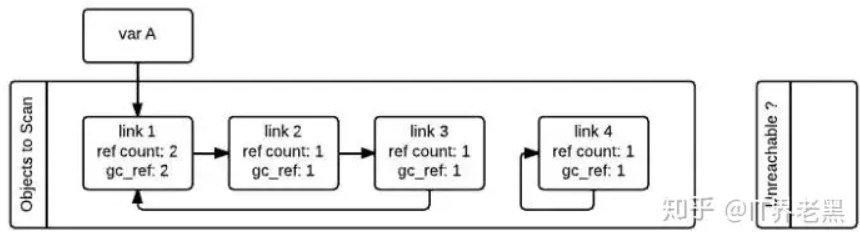
gc启动的时候,会逐个遍历”Object to Scan”链表中的容器对象,并且将当前对象所引用的所有对象的gc_ref减一。(扫描到link1的时候,由于link1引用了link2,所以会将link2的gc_ref减一,接着扫描link2,由于link2引用了link3,所以会将link3的gc_ref减一…..)像这样将”Objects to Scan”链表中的所有对象考察一遍之后,两个链表中的对象的ref_count和gc_ref的情况如下图所示。
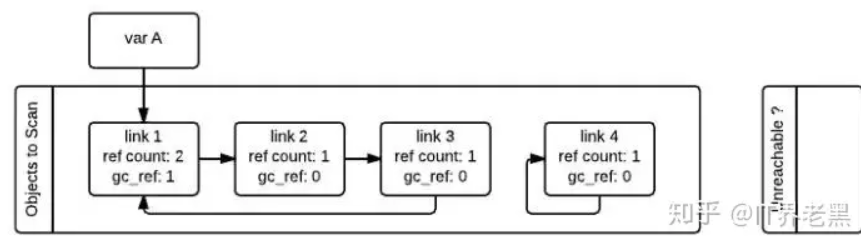
接着,gc会再次扫描所有的容器对象,如果对象的gc_ref值为0,那么这个对象就被标记为GC_TENTATIVELY_UNREACHABLE,并且被移至”Unreachable”链表中。如果对象的gc_ref不为0,那么这个对象就会被标记为GC_REACHABLE。
同时当gc发现有一个节点是可达的,那么他会递归式的将从该节点出发可以到达的所有节点标记为GC_REACHABLE.
除了将所有可达节点标记为GC_REACHABLE之外,如果该节点当前在”Unreachable”链表中的话,还需要将其移回到”Object to Scan”链表中
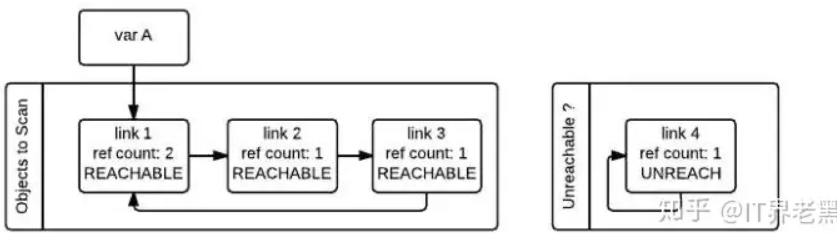
第二次遍历的所有对象都遍历完成之后,存在于”Unreachable”链表中的对象就是真正需要被释放的对象。如上图所示,此时link4存在于Unreachable链表中,gc随即释放之。
上面描述的垃圾回收的阶段,会暂停整个应用程序,等待标记清除结束后才会恢复应用程序的运行。
4.1.2 标记-清除缺点
标记-清除是一种周期性策略,相当于是一个定时任务,每隔一段时间进行一次扫描。
并且标记-清除工作时会暂停整个应用程序,等待标记清除结束后才会恢复应用程序的运行。
4.2 分代回收策略
分代回收建立标记清除的基础之上,因为我们的标记-清除策略会将我们的程序阻塞。为了减少应用程序暂停的时间,Python 通过“分代回收”(Generational Collection)策略。以空间换时间的方法提高垃圾回收效率。
分代的垃圾收集技术是在上个世纪 80 年代初发展起来的一种垃圾收集机制。分代回收是基于这样的一个统计事实,对于程序,存在一定比例的内存块的生存周期比较短;而剩下的内存块,生存周期会比较长,甚至会从程序开始一直持续到程序结束。生存期较短对象的比例通常在 80%~90% 之间,这种思想简单点说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集。这样在执行标记-清除算法时可以有效减小遍历的对象数,从而提高垃圾回收的速度
简单来说就是:对象存在时间越长,越可能不是垃圾,应该越少去收集
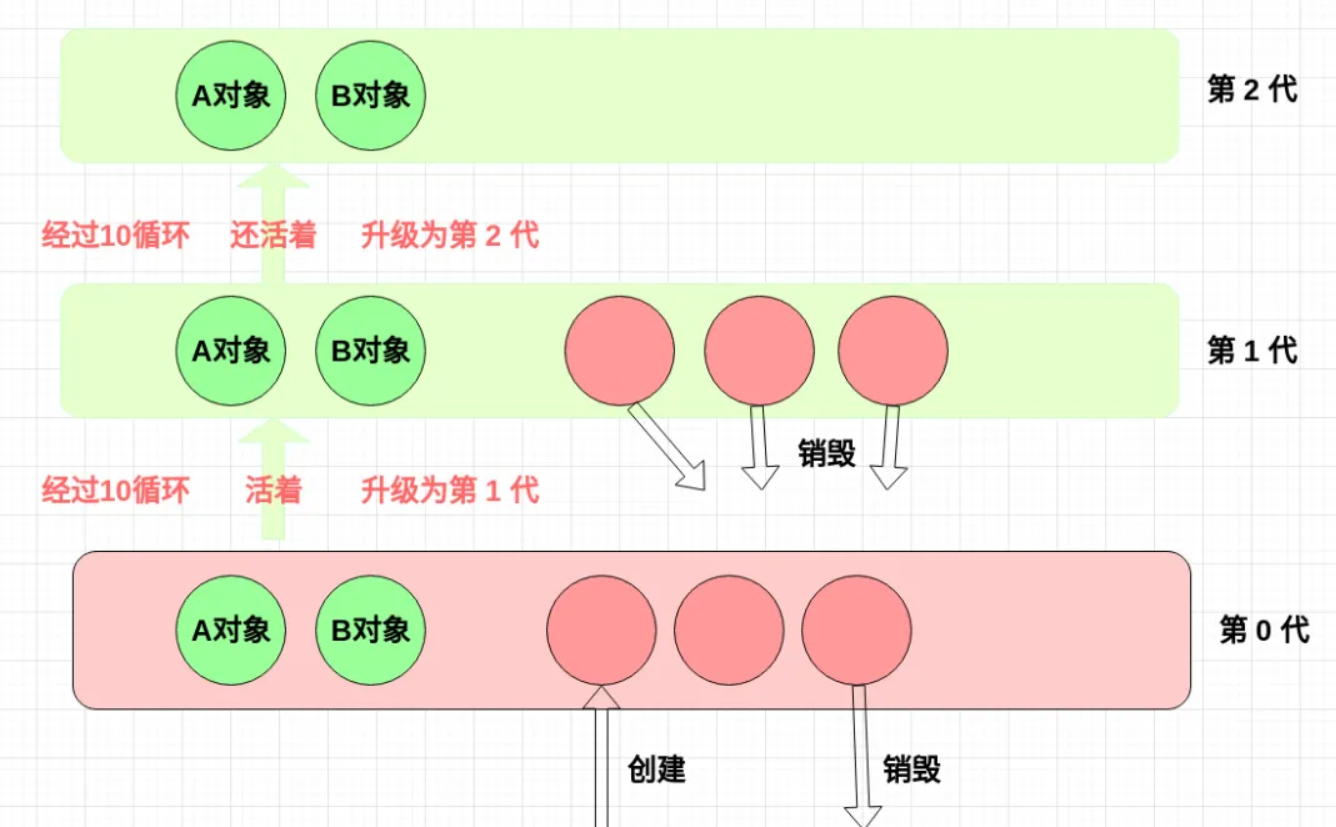
Python 将内存根据对象的存活时间划分为不同的集合,每个集合称为一个代,Python 将内存分为了 3“代”,分别为年轻代(第 0 代)、中年代(第 1 代)、老年代(第 2 代)。
每一个新生对象在generation zero中,如果它在一轮gc扫描中活了下来,那么它将被移至generation one,在那里他将较少的被扫描,如果它又活过了一轮gc,它又将被移至generation two,在那里它被扫描的次数将会更少。
值得注意的是当某一世代的扫描被触发的时候,比该世代年轻的世代也会被扫描。也就是说如果世代2的gc扫描被触发了,那么世代0,世代1也将被扫描,如果世代1的gc扫描被触发,世代0也会被扫描。
import gc
print(gc.get_threshold())
# (700, 10, 10)
# 上面这个是默认的回收策略的阈值
# 也可以自己设置回收策略的阈值
gc.set_threshold(500, 5, 5)● 700:表示当分配对象的个数达到700时,进行一次0代回收
● 10:当进行10次0代回收以后触发一次1代回收
● 10:当进行10次1代回收以后触发一次2代回收
5. python GC模块
● gc.get_count():获取当前自动执行垃圾回收的计数器,返回一个长度为3的列表
● gc.get_threshold():获取gc模块中自动执行垃圾回收的频率,默认是(700, 10, 10)
● gc.set_threshold(threshold0[,threshold1,threshold2]):设置自动执行垃圾回收的频率
● gc.disable():python3默认开启gc机制,可以使用该方法手动关闭gc机制
● gc.collect():手动调用垃圾回收机制回收垃圾
评论区