




转载地址: suredandan
K8s存储的前世今生
数据是最宝贵的资产,如何在K8s中存储数据是我们必须要掌握的。Kubernetes(K8s)在存储方面的进化可以从以下三个方面进行概述:第一个方面是存储方式从pod中独立出来,单独的生命周期;第二个方面是PV的创建从静态到动态;第三个方面是扩展方式从in-tree到out-of-tree的转变。
- 存储的独立性与生命周期管理:
- 初期:K8s中的容器存储是与Pod绑定的,如EmptyDir。这意味着当Pod被销毁时,与之关联的存储也会被销毁。
- 进化:为了满足持久化存储的需求,K8s引入了Persistent Volume(PV)和Persistent Volume Claim(PVC)的概念。PV是一个独立于Pod的存储资源,它有自己的生命周期,即使Pod被销毁,PV中的数据也不会丢失。PVC则是用户对存储的需求声明,它可以请求特定大小和访问模式的PV。
- 从静态存储到动态存储的转变:
- 静态存储:最初,管理员需要预先创建一定数量的PV,然后用户通过PVC来请求使用这些PV。这种方式存在一定的不灵活性,因为需要管理员预估存储需求。
- 动态存储:为了解决静态存储的局限性,K8s引入了动态存储供应(Dynamic Storage Provisioning)。这允许管理员定义存储类(StorageClass),当用户创建PVC时,系统会根据StorageClass自动创建对应的PV,从而实现动态供应。
- 存储插件的扩展方式:
- In-tree:最初,K8s的存储插件是直接集成在K8s代码库中的,这被称为in-tree插件。这种方式的问题是,每当要支持新的存储解决方案时,都需要修改K8s的核心代码。
- Out-of-tree:为了提高扩展性,K8s引入了Container Storage Interface(CSI)。CSI允许存储提供商开发自己的存储插件,并与K8s集成,而无需修改K8s的核心代码。这大大提高了存储解决方案的多样性和扩展性。
这三个方面的进化反映了K8s在存储方面的持续创新和完善,以满足不断变化的业务需求。。
从共生到独立
当我们在pod中运行了应用,而没有挂载任何存储的时候,它会和docker中的使用一样,默认放在节点对应的docker的/var/lib/docker目录。而应用输出的日志或者配置文件等等一些信息是无法去读取或者更改的。在docker中,我们可以使用-v的选项将存储外挂。在k8s中,我们则是使用卷(volume)来定义存储和挂载存储。形式如下:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: test-container
image: k8s.gcr.io/busybox
volumeMounts:
- name: cache-volume
mountPath: /cache
volumes:
- name: cache-volume
emptyDir: {}
从上面的关键字,我们可以看到在pod中使用存储,有两处关键字,一处是volumes,一处是volumeMounts。前者是指挂载的存储是什么,后者是告诉pod,挂载什么目录,它们两者是用name来进行关联的。
需要注意的是volumes支持挂载非常多的类型,例如本地磁盘、网络磁盘、配置文件、第三方插件FlexVolume、CSI等。这样一来,存储的使用就非常灵活,可以根据场景做具体地选择。
使用volume有什么好处呢?好处有三:
- 第一,挂载的路径上的数据可以使用外部目录的数据来替换。比如在使用配置文件的好场景,在使用了卷就可以对同样的镜像挂载不同的数据源的配置,从而达到访问不同的环境的目的。
- 第二,Pod 中的所有容器都可以访问这个卷,从而允许这些容器共享数据。
- 第三,特定的卷如本地磁盘、网络磁盘等卷类型,允许 Pod 中的数据持久保留下来,即使其中的容器需要重新启动。
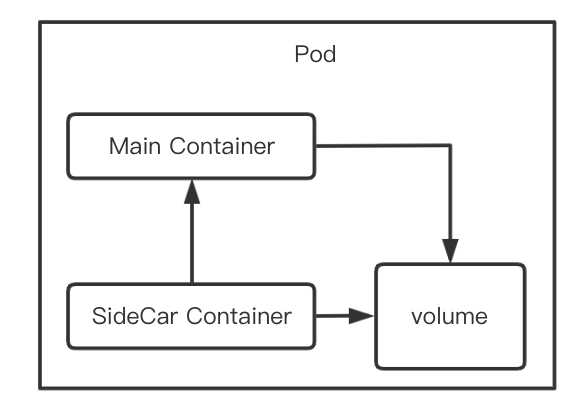
K8s提出volume的意义在于提供了“声明”式定义,将使用者和提供者分离。剩下的卷类型和卷的生命周期都是围绕这个来扩展的。
我们把应用部署到pod中,在没有使用卷的时候,即使对里面的数据进行了修改,但是数据的生命周期是随着pod的生命同生共死的。而使用了卷后,只要指定了“特定”的卷类型,就可以利用它的特性,让数据的生命周期不再依赖于pod的生命周期。比如我们外挂一个nfs的存储,如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploytest-nfs
spec:
replicas: 1
template:
...
spec:
containers:
- image: registry.cn-hangzhou.aliyuncs.com/sure/tomcat:8.0
name: deploytest-nfs
...
volumeMounts:
- mountPath: /usr/local/tomcat/logs/
name: log
volumes:
- name: log
nfs:
server: 192.168.100.200
path: "/srv/nfs/share"
很容易看出,数据存储在容器外的nfs服务器上,被持久化了。即使pod关闭了,pod中的log数据仍然存放在nfs服务器上。
但是,这个例子也有一个不好的地方,就是pod与nfs的配置太耦合了。例如当nfs的服务器地址发现了变化,我们就不得不去改变对应的pod中的服务器地址。
那么怎么去解决这个问题呢?为了让Volume中的数据持久化,K8s抽象了PV(PersistentVolume)来定义和使用存储。它可以将存储和计算分离,通过不同的组件来管理存储资源和计算资源,让使用者不用关心具体的基础设施,当需要存储资源的时候,只要像CPU和内存一样,声明要多少即可。这样依赖,解耦了Pod和Volume之间生命周期的关联。当Pod删除后,它使用的PV仍然存在,还可以被新建的Pod复用。
在pod中使用pv的方式是,在volume字段使用PVC(PersistentVolumeClaim)这种类型。而PVC再去实际的PV进行关联。在PVC中声明需要的资源大小和访问模式等需求,而不需要关心存储实现细节。PV是存储的实际信息的承载体。PV和对应的后端存储信息交由集群管理员统一运维和管控,安全策略更容易控制。
站在更高一个角度看待volume以PV的形式分离出来的原因是:如果不分离,则要求先存在实际的存储资源,才能够使用;而分离的资源,可以让pod使用存储的入口和存储本身分离,不要求现有存储后有pod,解耦了pod和存储资源,通过绑定的方式来使用。
当Pod中的Volume使用PVC后,新的配置会发生下面一些变化:deployment变化的部分是volumes,将原有的 nfs 的相关信息,变为了对一个 PVC 的引用。如下所示:
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploytest-nfs
namespace: default
spec:
...
volumes:
- name: nfs
persistentVolumeClaim:
claimName: nfs-pvc
而 NFS的配置信息放在pv中,pvc的定义如下:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv
spec:
capacity:
storage: 100Mi
accessModes:
- ReadWriteMany
nfs:
server: 192.168.100.200
path: "/srv/nfs/share"
通常情况下,PV 对象是由运维人员事先创建在 Kubernetes 集群里待用的。比如,本例总中的 NFS 类型的 PV。
而PVC 描述的,则是 Pod 所希望使用的持久化存储的属性。比如,Volume 存储的大小、可读写权限等等。
PVC 对象通常由开发人员创建;或者以 PVC 模板的方式成为 StatefulSet 的一部分,然后由 StatefulSet 控制器负责创建带编号的 PVC。
PVC的配置如下:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: nfs-pvc
namespace: default
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
resources:
requests:
storage: 90Mi
(1)从上面的yaml文件可以看到,当使用了 PV和 PVC 后,当在deployment 中使用 Volume与 Volume 真正使用的是何种存储类型不再强关联。deployment 使用 PVC 时只需要写上 PVC 的名字;PVC只需要声明访问模式和所需要的大小;在 PV 中才需要真正配置 NFS 的相关信息。
(2)这样松耦合带来了一个好处,PV使用什么存储类型和 deployment 无关。
(3)细心的读者会发现,为什么没有设置 PV 与 PVC 的绑定的相关配置呢?这是因为PV 和 PVC 做绑定,是一个自动的过程。想要用户创建的 PVC 要真正被容器使用起来,就必须先和某个符合条件的 PV 进行绑定。这里要检查的条件,包括两部分:
- 第一个条件,当然是 PV 和 PVC 的 spec 字段。比如,PV 的存储(storage)大小,就必须满足 PVC 的要求。
- 第二个条件,则是 PV 和 PVC 的 storageClassName 字段必须一样。这个机制我会在本篇文章的最后一部分专门介绍。
当满足了;上面两个条件后,它们就会自动绑定。它们的绑定其实和 K8s 中的 label 的设计又有点像。为什么这样说呢?因为PV 和 PVC 绑定的两个关键点就是符合就绑定。这个就和 label 很像了,符合就 select。
(4)不难发现,PV 需要创建,我们可以创建100M 的 PV,也可以创建90M 的 PV,它们都可以与定义的 PVC 进行绑定,绑定的原则就是访问模式+更接近的容量大小。
(5)在上面的例子中,我们如果只创建PVC,不去创建PV,那么PVC的状态就会一直是pending的状态,而pod也不会创建成功。这个就涉及到pvc-pv的状态迁移的概念。我们在后面章节专门讲解。
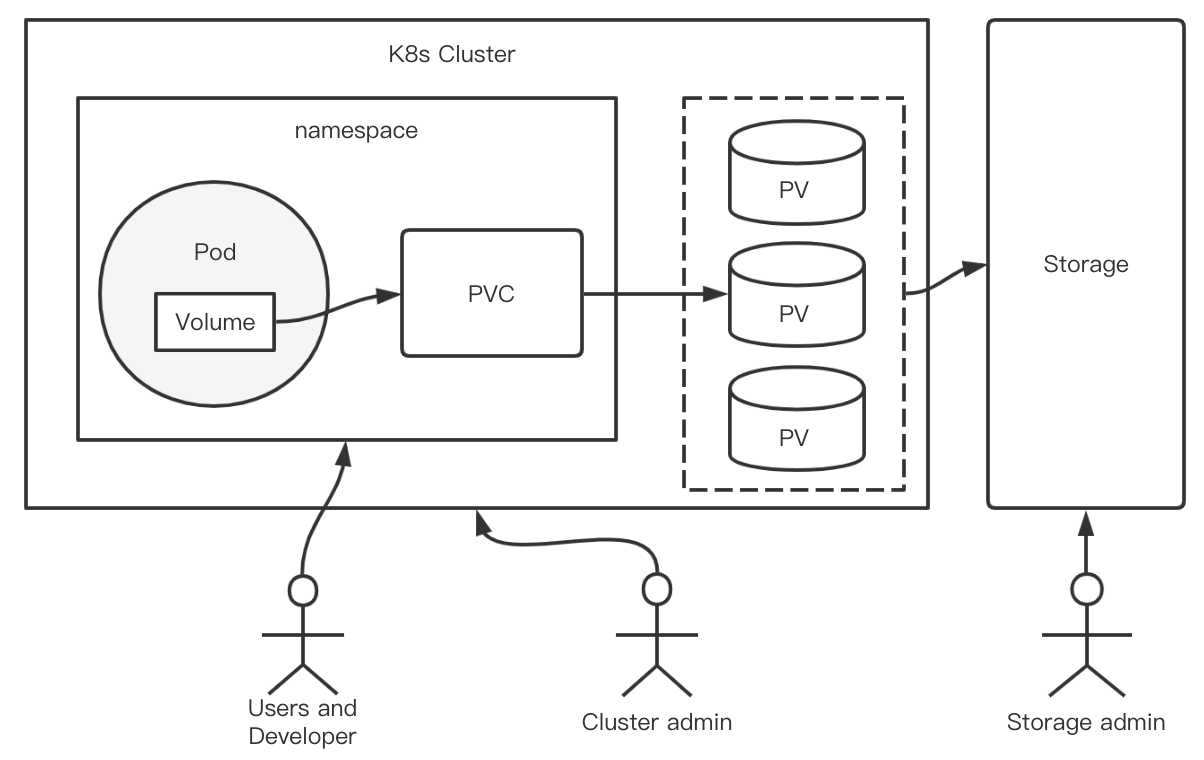
打一个不是特别恰当的比方:Pod好比我们的笔记本,我们将业务数据存放在D盘中,数据的生命周期和笔记本紧密相关。如果笔记本损坏了那么磁盘里的数据就不能再被访问。所以,往往我们可能将一些重要的数据放在外接的移动硬盘上,这个时候就用D盘去映射这个外接的磁盘,这样一来,数据真正都存放在外部的磁盘上了。这样就算笔记本坏掉了,数据也不会受影响。换句话说,就是数据的生命周期与笔记本无关。
从静态到动态
上面,我们说了如果只创建PVC,不去创建PV,那么PVC的状态就会一直是pending的状态。所以我们就得手工去创建能匹配PVC的PV。这个就是kubernetes中PV的静态创建。
那么,我们有没有想过这样一个问题:用户的Pod声明了PVC,Kubernetes会寻找一个PV配对,如果没有合适的PV,是不是就会一直“傻乎乎”地等着呢?Pod调度都有优先级抢占机制,那PVC呢?
这个时候就轮到StorageClass闪亮登场。StorageClass 的作用,是充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起。StorageClass 的另一个重要作用,是指定 PV 的 Provisioner(存储插件)。这时候,如果存储插件支持 Dynamic Provisioning 的话,Kubernetes 就可以自动创建 PV 了。
StorageClass被定义好后,当PVC的需求来了,它就会动态的去创建PV,这样一来PV的创建就从“静态”来到了“动态”。
从内到外
Kubernetes 内置了非常多的存储插件,我们称这些内置的存储插件类型称之为in-tree类型的存储插件。In-tree插件代码存在于k8s主库,如 gce-pd、azureFile、ceph、nfs等。从这些卷插件我们也能看出Kubernetes社区参与厂家越来越多了,Kubernetes的影响力也再不断地扩大。
在欣喜Kubernetes存储生态繁荣之余,最“头疼”的应该就是Kuberntes SIG Storage。如此多待实现的存储驱动需求,如果按照之前全部in-tree的套路,这种方式需要将后端存储的代码逻辑放到K8S的代码中运行,调用引擎与插件间属于强耦合,这种方式类似Docker以前在k8s中的问题,会带来一些问题:
(1)存储插件需要随同K8s一起发布。K8s如果一直没有将这些插件功能合并进发布版本,那这些存储插件也使用不了。
(2)K8S社区需要对存储插件的测试、维护负责。如果插件存在问题,就有可能会影响K8s的正常运行。
(3)存储插件享有K8s组件同等的特权,有可能存在安全隐患。
因此,为了解决或者规避这些问题,就得想个法子把in-tree的代码剥出去,或者不再沿用in-tree的这种模式,所以就诞生了out-of-tree的方案。
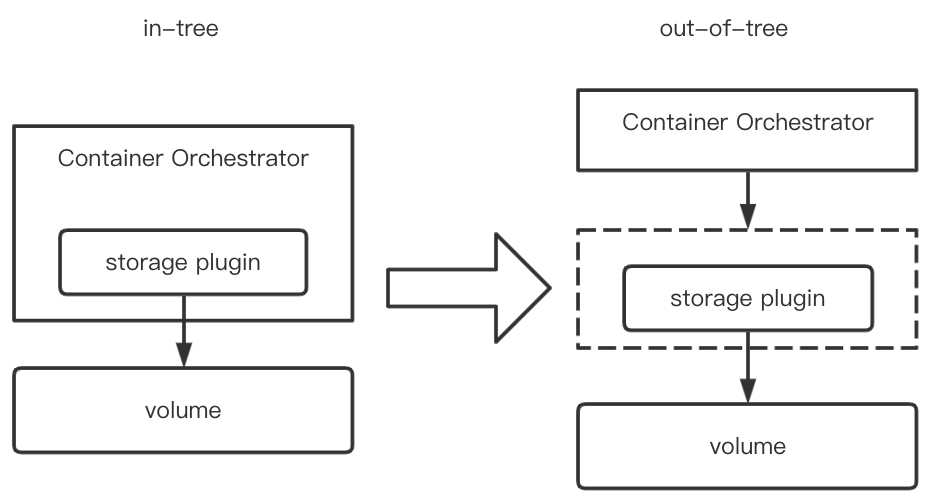
Out-of-tree提供了存储插件的接口定义和使用方案,外部为特定存储实现这些接口,按照使用方案部署即可。
– FlexVolume框架: 使用基于 exec 的模型来与驱动程序对接。用户必须在每个节点(在某些情况下是主节点)上的预定义卷插件路径中安装FlexVolume驱动程序可执行文件。由kubelet主动发起调用,调用方式为exec命令行,包含接口mount/unmount/attach/detach。k8s 1.2版本引入。
- CSI框架: 基于Container Storage Interface(CSI) specification的插件实现。CSI specification包含了Provisioner和挂载/卸载的接口,以及更多的扩展接口(resize/snapshot…)。在k8s中,通过watch特定资源变化并转换成rpc接口调用,以及由kubelet直接通过rpc接口进行调用使用CSI插件。k8s 1.9引入对CSI的alpha支持,k8s 1.13 GA。
In-tree的方式代码和k8s主库耦合,不利于迭代,增加了主库复杂度,因此当前很多In-tree的插件都在向out-of-tree模式迁移。
Kubernetes现在对外支持的out-of-tree插件接口分别是FlexVolume和CSI。FlexVolume自身有一些缺陷,比如权限和过度依赖环境等。而且,它仅仅是基于K8s自身存储的out-of-tree解决方案,并不在其它oc下通用。为了改善FlexVolume的问题,以及做到OC行业使用统一的方式使用容器存储,所以就自然而然诞生了CSI。它也是当前kubernetes所推崇的存储扩展方案。
至此,我们对kubernetes的存储进行了一个大体的介绍,接下来开始深入它。
评论区