




书籍:待上传
前沿
本书在继续关注高性能之外,还用了较多的篇 幅来介绍如何实现MySQL的大规模可扩展应用和合规性问题
MySQL架构
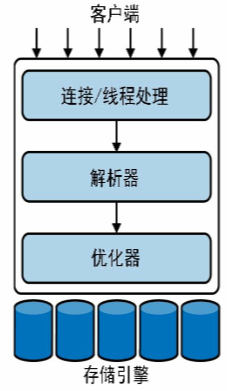
最上层的客户端所包含的服务并不是MySQL独有的,大多数基于网络 的客户端/服务器工具或服务器都有类似的服务,包括连接处理、身份 验证、确保安全性等。
第二层是比较有意思的部分。大多数MySQL的核心功能都在这一层, 包括查询解析、分析、优化、以及所有的内置函数(例如,日期、时 间、数学和加密函数),所有跨存储引擎的功能也都在这一层实现:存 储过程、触发器、视图等。
第三层是存储引擎层。存储引擎负责MySQL中数据的存储和提取。和 GNU/Linux下的各种文件系统一样,每种存储引擎都有其优势和劣势。 服务器通过存储引擎API进行通信。这些API屏蔽了不同存储引擎之间 的差异,使得它们对上面的查询层基本上是透明的。存储引擎层还包含 几十个底层函数,用于执行诸如“开始一个事务”或者“根据主键提取一 行记录”等操作。但存储引擎不会去解析SQL[1],不同存储引擎之间也 不会相互通信,而只是简单地响应服务器的请求
并发控制
读写锁
处理并发读/写的访问系统包含以下2种锁
共享锁(读锁)
排他锁(写锁)
锁的粒度
锁的操作需要消耗系统开销,锁的策略是锁开销和数据安全性之间的平衡,一般选择再表施加行级锁,每个存储引擎均有自己锁实现方式
表锁:开销最小的策略,锁定整张表
行级锁:最大程度支持并发处理
事务
ACID
ACID:原子性、一致性、隔离性、持久性
隔离级别
READ UNCOMMITTED:事务可以查看其它事务未提交的修改,脏读
READ COMMITED:提交读,事务可以看到其他事务在它之后提交的修改,但是其它事务在该事务提交之前看不到修改,同一事务执行2次,可以看到不同的数据
REPEATABLE READ(可重复读):保证事务在多次读取同一ID的数据结果一致,但是存在其它事务在当前事务读取范围内插入记录,导致事务读取到插入的记录,出现缓读,InnoDB和XtraDB存储引擎通过多版本并发控制(MVCC, Multiversion Concurrency Control)解决了幻读的问题
SERIALIZABLE(可串行化):强制事务按照顺序执行,解决事务冲突,并发性能丢失

死锁
多个资源互相持有请求相同资源的锁,产生循环依赖
锁循环依赖检测
锁超时机制
将持有最少行级锁的事务-回滚
事务日志
存储引擎只需要修改内存的数据副本,将记录写入事务日志,事务日志持久化在本地硬盘,事务日志视在硬盘一小块区域采用追加顺序IO的策略写入,后台有进程将事务日志持久化到表里(write-ahead logging,预写式日志)
Mysql里的事务
AUTOCOMMIT:单个INSERT、UPDATE或DELETE语句会被隐式包装在 一个事务中并在执行成功后立即提交,这称为自动提交,禁用此模式,可以在事务中执行一系列 语句,并在结束时执行COMMIT提交事务或ROLLBACK回滚事务!
注意:
某些DDL操作会导致事务自动提交
禁止在事务里混用存储引擎
隐式锁定和显示锁定
InnoDB使用两阶段锁定协议(two-phase locking protocol)。在事务执行 期间,随时都可以获取锁,但锁只有在提交或回滚后才会释放,
InnoDB会根据隔离级别自动处理锁
需要注意区分命令是在服务器级别还是在存储引擎 实现的命令,事务需要在存储引擎里实现!
多版本并发控制
数据在某个时间节点的快照, InnodDB在事务第一次读取数据分配时候,分配该ID
MVCC仅适用于REPEATABLE READ和READ COMMITTED隔离级别
复制
数据结构
表元数据:.ibd文件中,不再仅仅依赖information_schema来检索表定义 和元数据,而是引入了字典对象缓存,这是一种基于最近最少使用 (LRU)的内存缓存,包括分区定义、表定义、存储程序定义、字符集 和排序信息。特别是当前访问最活跃的那些表,在缓存中最常出 现。每个表的.ibd和.frm文件被替换为已经被序列化的字典信息 (.sdi)
InnoDB引擎
InnoDB不只 锁定在查询中涉及的行,还会对索引结构中的间隙进行锁定,以防止幻 行被插入
可靠性工程世界中的监控
SLI
服务水平指标
SLO
服务水平目标
SLA
服务水平协议
三个关键方面:延迟、可用性、错误
Performance schema
提供数据库内部的操作上底层指标
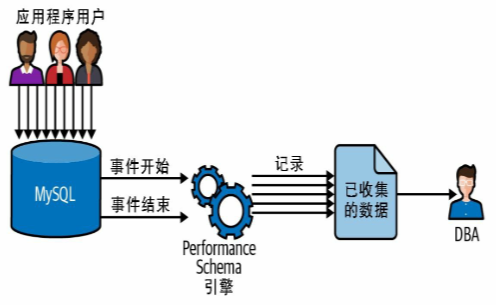 将程序插桩探测代码收集信息,将信息记录到表,消费者表是插桩发送信息的目的地。测量结果存储在 Performance Schema数据库的多个表中。
将程序插桩探测代码收集信息,将信息记录到表,消费者表是插桩发送信息的目的地。测量结果存储在 Performance Schema数据库的多个表中。
操作系统 和 硬件优化
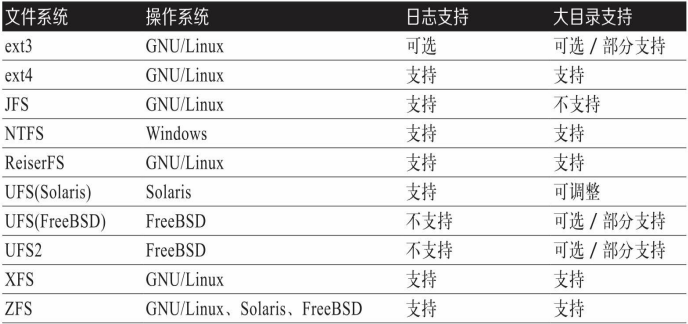
理解文件系统限制和Linux I/O调度器
IO:写顺序日志允许在内存中更改页面,而不用将更改刷新到磁盘,这通常涉及随机I/O,速度非常慢(多次写操作和IO合并)
RAID: 存储引擎将数据和索引存在单个大文件
网络配置
文件系统:需要处理高并发、多文件、碎片等,日志型文件系统最佳
磁盘队列调度器
内存和交换
优化服务器设置
正确的做法是:保持正确的基本设置,只有极少数配置是重要的,经更多时间花在schema优化、索引和查询设计上
InnoDB缓冲池和日志文件大小设置
任何需要永久使用的设置都应该写入全局配置文件
警告:禁止建议基准测试套件,迭代修改配置来调优服务器,对时间视巨大的浪费
MySQL不是严格控制内存分配的数据库
配置内存
用innodb_dedicated_server通常会占用50%~75%的内存。这样,至少有25%的内存可用于每个连接的内存分配、操作系统开销和其他内存设置
innodb_dedicated_server,它可以处理90%的性能配置。
最重要的两个选项是:
● innodb_buffer_pool_size
● innodb_log_file_size
innoDB 缓冲池
最重要的变量:InnoDB缓冲池不仅缓存索引,还缓存行数据、自适应哈希索引、更改缓冲区、锁和其他内部结构等,延迟合并写操作。
关闭时候对脏页和启动时候预热时间更长
线程缓存
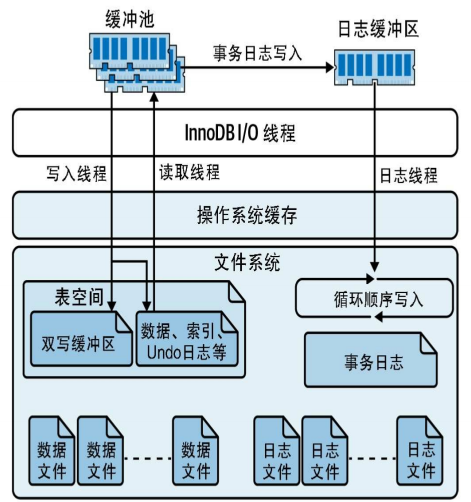
InnoDB事务日志
InnoDB使用日志来降低提交事务的成本。它不会在每个事务提交时将缓冲池刷新到磁盘,而是将事务记录到日志中。事务对数据和索引所做的更改通常映射到表空间中的随机位置,因此将这些更改刷新到磁盘将需要随机I/O。日志文件大小固定,循环写入。
InnoDB表空间
InnoDB将数据保存在表空间中,表空间本质上是一个虚拟文件系统,由磁盘上的一个或多个文件组成。InnoDB将表空间用于多种用途,而不仅仅是存储表和索引。表空间中还包含了Undo日志(重新创建旧行版本所需的信息)、修改缓冲区、双写缓冲区和其他内部结构。
配置Mysql并发
innodb_thread_concurrency变量,变量限制了内核中同时可以有多少线程。与CPU核数相同,然后再调整
innodb_commit_concurrency变量控制着可以同时提交的线程数
安全配置
高级设置
Schema设计与管理
逻辑设计、物理设计、查询执行,三者关系
优化的数据类型
最小数据类型:占用磁盘、内存和CPU缓存空间更少,CPU处理周期更少
简单数据类型:数字、字符串、时间等
同类型的不同子类型差异
避免存储NULL
基本数据类型
整数类型
实数类型
varchar:字符串咧最大长度远大于均值长度
char:短字符串,尾空格截断
binary和varbinary与上面类似
备注:MySQL内存分配通常是固定内存块,不利于可变类型导致临时表排序和操作。因此可变的最好只分配真正的需要的空间
blob和text:存储很大数据设计的字符串类型,以2进制和字符方式存储
使用枚举代替字符串,设计实践是使用带整数主键的“查找表”,避免在联接中使用字符串
时间和日期类型,大多数是没有其他选择,只有在存储日期和时间需要考虑DATETIME和TIMESTAMP
位压缩数据类型
BIT
SET
json
空间总表和查询速度开销都比SQL大
标识符:
引用行及通常使其唯一的方式
整数类型:AUTO_INCREMENT,用尽会报错主键冲突
对于标识符来说,ENUM和SET类型通常是糟糕的选择
字符串类型,消耗空间且速度比整数类型慢
特殊数据类型
Schema设计陷阱
太多列:MySQL的存储引擎API通过在服务器和存储引擎之间以行缓冲区格式复制行来工作;然后,服务器将缓冲区解码为列。将行缓冲区转换为解码列的行数据结构的操作代价是非常高的
太多联接:实体属性entity attribute value设计模式是一种糟糕的设计模式,高并发快速查询,最好少于十几个表
过度使用枚举
NULL不是虚拟值
schema管理
不要让修改schema成为业务瓶颈,如何将shcema变更管理视为“数据存储平台”的一部分
将shcema管理与持续集成相结合,与CI管道集成
非阻塞schema更改和阻塞schema更改
Percona的pt-online-schema-change和GitHub的gh-ost
创建高性能的索引
索引类型
不同存储引擎的索引工作方式不一致
B-tree索引&b+tree索引
自适应哈希索引
以上索引对下列查询类型生效
全值匹配
匹配最左前缀
匹配列前缀
匹配范围值
精确匹配某一列而范围匹配另外一列
只访问索引的查询
全文索引


更多索引学习:议阅读由Tapio Lahdenmaki和Mike Leach编写的Relational Database Index Design and the Optimizers(Wiley出版社出版)一书,
查询性能优化
非常重要,值得细看和考虑实际开发设计

复制

备份与恢复
使用Percona XtraBackup和MySQL Enterprise Backup中的增量备份特性。
备份二进制日志。可以在每次备份后使用FLUSH LOGS来开始记录一个新的二进制日志,这样就只需要备份新的二进制日志。
全量备份
LVM快照
MySQL合规性

评论区