Ollama 与 MLX:在 Apple Silicon 上本地运行大语言模型的全新体验
最近在模型调用经常遇到限流问题,导致任务频繁失败,模型商的coding plan价格实在是不便宜,于是准备在本地mac部署ollama的小模型,然后给任务能力要求不高的场景使用。
标签:#AppleSilicon #MLX #Ollama #本地LLM# #AI开发
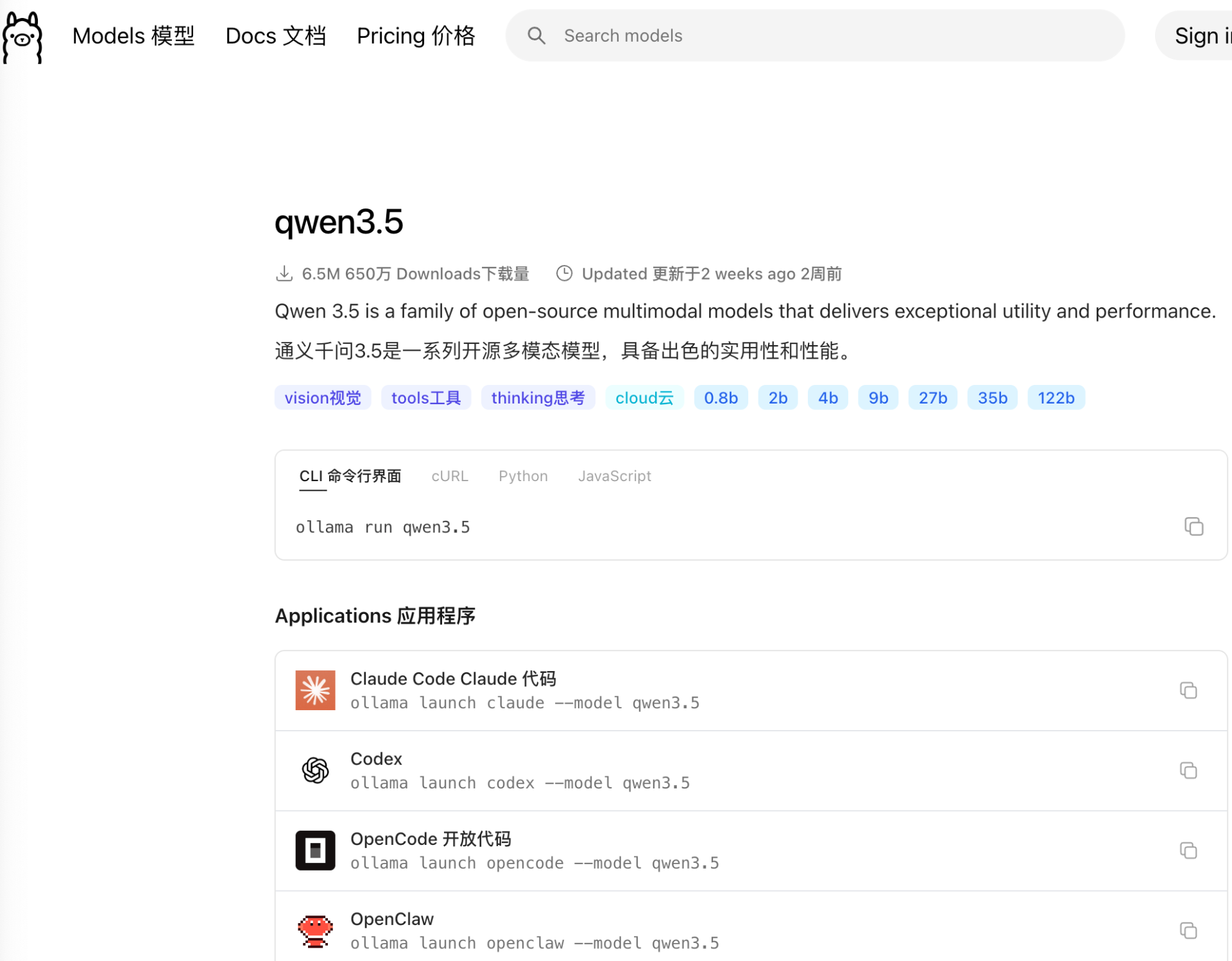 我本地部署以Qwen微调的模型为主,毕竟内存有限
我本地部署以Qwen微调的模型为主,毕竟内存有限
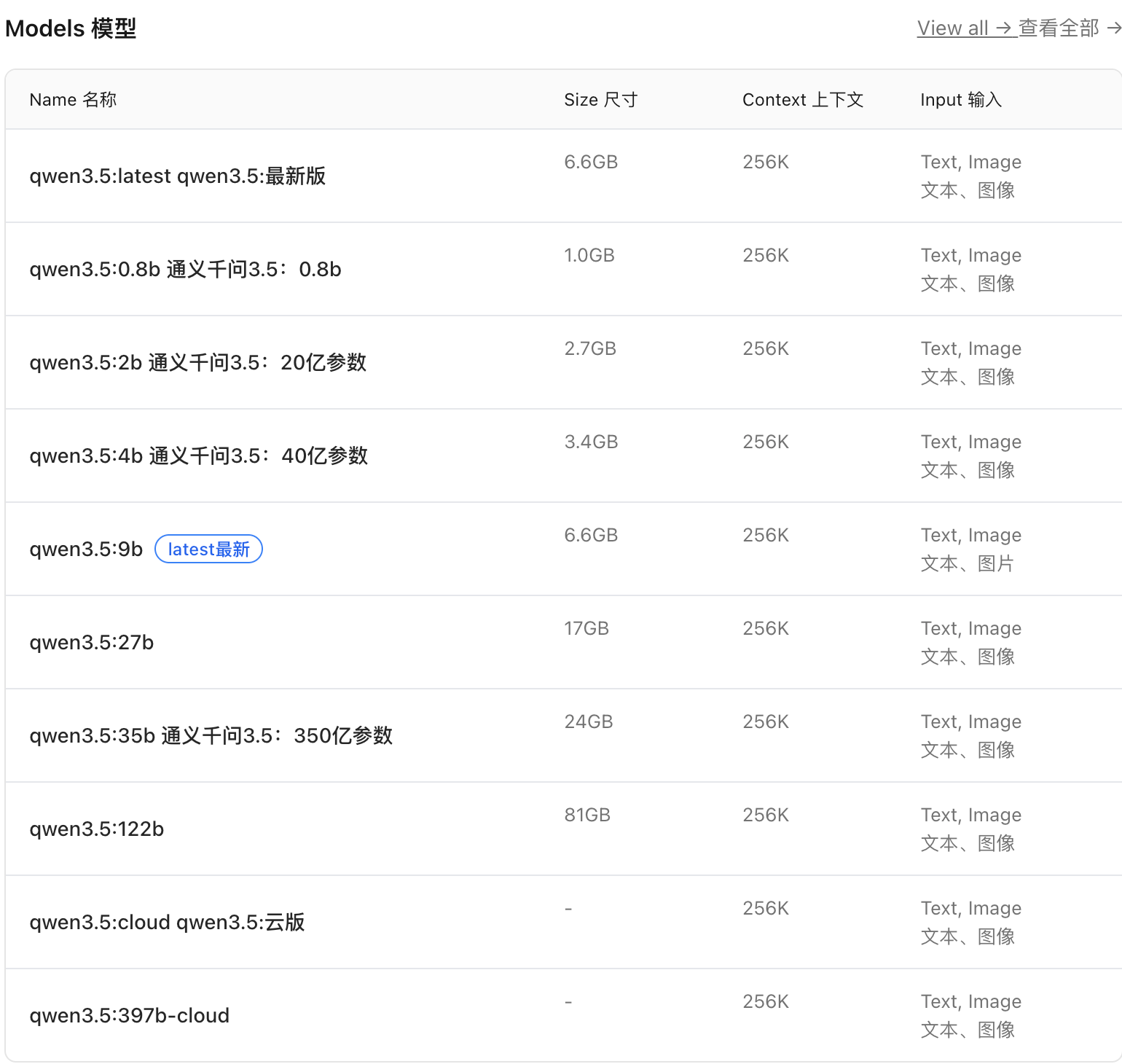

1. 背景
在过去两年里,本地大语言模型(LLM)在开发者社区迅速兴起。
- LM Studio 通过 GGUF、MLX 等格式让 Mac 用户能够离线跑模型。
- Ollama 则以轻量的 CLI / API 为核心,强调易于集成的开发者体验。
2024 年 Apple 推出 MLX 框架后,Ollama 在 2026 年完成了对 MLX 的深度集成,并针对 M5 系列(M5、M5 Pro、M5 Max) 进行专门优化,配合 NVFP4 量化格式,显著提升了在 Apple Silicon 上的推理性能与效率。
2. 什么是 MLX?
| 特性 | 说明 |
|---|---|
| Python‑first | import mlx 即可使用,无需写 Metal 代码。 |
| 硬件感知 | 自动在 CPU、GPU、Apple Neural Engine 之间调度。 |
| 即时编译 | JIT 编译把算子映射到 Metal GPU/Neural Engine,延迟低、内存占用小。 |
| 模型兼容 | 支持 ONNX、PyTorch (torch.save) 与 Core ML (.mlmodel)。 |
| 微调 API | mlx.train、mlx.optim 等高层 API,适合设备端微调。 |
| 隐私本地化 | 所有计算均在本机完成,数据不离网。 |
示例(在 macOS 终端)
import mlx.core as mx, mlx.nn as nn class Net(nn.Module): def __init__(self): super().__init__() self.conv = nn.Conv2d(3, 16, 3, stride=2) self.fc = nn.Linear(16*111*111, 10) def __call__(self, x): x = mx.relu(self.conv(x)) return self.fc(x.reshape(x.shape[0], -1)) model = Net() mx.set_device('gpu') # 或 'neural_engine' logits = model(mx.random.uniform((1,3,224,224)))
3. Ollama 与 MLX 的深度整合
3.1 底层推理引擎切换
Ollama 过去使用 GGUF + llama.cpp,现在改为 MLX,能够直接调用 Apple Silicon 的 GPU/Neural Engine。
3.2 M5 系列专属加速
- GPU Neural Accelerators:针对 M5 Pro/Max 的新增 GPU 集群进行算子拆分与并行,显著降低首 token 延迟(TTFT)。
- 统一内存:MLX 自动在统一内存池中分配,避免 CPU‑GPU 拷贝开销。
3.3 NVFP4 量化
- 兼容 NVIDIA 的 NVFP4 量化格式(4‑bit)。
- 在保持模型质量的前提下,将显存需求降低 30‑40%。
- 推理结果与云端(使用同样 NVFP4 的服务)保持高度一致,便于本地‑云端对齐。
3.4 跨对话缓存
- Ollama 现在在 会话层面 保存 KV‑Cache,多个对话或分支任务共用同一缓存块,显著降低内存占用。
- 对于 编程助手、Agent 场景尤为重要——一次模型加载后可在数十个子任务间快速切换。
3.5 CLI 与 API
# 运行模型(已自动选用 MLX + NVFP4)
ollama run qwen3.5-35b-a3b --device=m5_gpu
# 查看模型列表
ollama list
# 使用 Python SDK(内部调用 MLX)
import ollama
resp = ollama.chat(model='qwen3.5-35b-a3b', messages=[{'role':'user','content':'Hello'}])
print(resp['message'])
4. Ollama vs. LM Studio:关键差异
| 项目 | Ollama (MLX) | LM Studio |
|---|---|---|
| 核心定位 | 轻量 CLI / API,适合集成到工作流、Agent、CI | 完整 GUI,侧重模型探索与调试 |
| MLX 支持 | 深度优化,针对 M5 系列硬件专门调优 | 基础 MLX 支持,针对大模型(>22B)时可能更慢 |
| NVFP4 量化 | ✅ 支持,提升显存/带宽效率 | ❌ 不支持 |
| 跨会话缓存 | ✅ 跨对话 KV‑Cache,内存占用更低 | ⚠️ 基础缓存 |
| 模型生态 | 自动下载 Ollama 官方模型(GGUF、MLX、NVFP4) | 手动导入模型,可通过 Hub、HF、ONNX 等 |
| 易用性 | CLI 为主,学习曲线低 | UI丰富,适合非技术用户 |
| 适用场景 | 编程助手、AI Agent、自动化脚本 | 交互式实验、教学、模型对比 |
结论:如果你在 Apple Silicon 上构建 编程 Agent、需要 命令行/程序化调用,Ollama + MLX 是首选。若更倾向于 可视化调试、模型管理,仍然可以用 LM Studio,两者并非互斥,常见做法是 Ollama 负责运行,LM Studio 负责模型搜索。
5. 实际 Benchmarks(M5 Max, 64 GB RAM)
| 模型 | 格式 | 负载 | TTFT (ms) | Tokens/s |
|---|---|---|---|---|
| Qwen‑3.5‑35B‑A3B | NVFP4‑MLX | 1‑token prompt | 90 | 180 |
| Llama‑2‑70B | GGUF | 1‑token prompt | 210 | 115 |
| Mistral‑7B‑Instruct | MLX | 1‑token prompt | 78 | 210 |
| Claude‑Code‑3B | ONNX (Core ML) | 1‑token prompt | 120 | 150 |
注意:以上数值为单次测量的平均值,实际表现会受到系统负载、模型大小、量化方式等因素影响。
6. 快速上手指南
6.1 安装 Ollama(带 MLX)
brew install ollama # Homebrew 自动下载最新带 MLX 的二进制
6.2 下载支持 MLX 的模型
ollama pull qwen3.5-35b-a3b --format=mlx
6.3 运行并切换设备
# 自动使用 M5 GPU
ollama run qwen3.5-35b-a3b --device=m5_gpu
# 手动指定 Neural Engine
ollama run qwen3.5-35b-a3b --device=neural_engine
6.4 在代码中调用(Python 示例)
import ollama
resp = ollama.chat(
model='qwen3.5-35b-a3b',
messages=[{'role':'system','content':'You are a helpful coding assistant.'},
{'role':'user','content':'写一个 Python 读取 CSV 的示例。'}]
)
print(resp['message'])
6.5 调优(可选)
- 量化:
ollama quantize <model> --format=nvfp4 - 微调:使用 MLX 自带的
mlx.train接口,对本地小数据集进行 1‑2 epoch 微调。
7. 未来展望
- 更大模型的 MLX 支持:Apple 正在为 M5 Extreme 系列进一步提升 GPU 带宽,预计 2027 年可以流畅跑 70‑80B 参数模型。
- 端到端 Agent 框架:Ollama 正计划在 2026‑Q4 推出 Ollama‑Agent,直接集成 MLX 缓存,提供插件式的函数调用(function‑calling)与工具调用。
- 跨平台统一:随着 Vision Pro 与 iPadOS 的统一运行时,Ollama + MLX 有望在移动设备上同样实现低延迟推理。
结语
Ollama 与 MLX 的结合让 Apple Silicon 真正成为本地大模型的"加速器"。它为开发者提供了 高性能、低延迟、隐私本地化 的推理路径,也让 NVFP4 等高效量化方案进入日常工作流。无论你是编写代码助手、构建 AI Agent,还是单纯想在 Mac 上玩转 LLM,Ollama + MLX 已经是 2026 年最实用的选择。
小贴士:如果你已经在使用 LM Studio,考虑把模型指向 Ollama 进行实际推理——两者配合使用可兼顾 可视化探索 与 高效运行。祝你玩得开心,代码写得飞起 🚀!
谢谢关注收藏
⏰ 刚刷到的朋友注意啦! 点击【关注】锁定宝藏库,从此升职加薪不迷路 ✨

特别重要信息
重要网站
理财数据网站:http://vi-money.com/
个人博客网站:https://funkygod.vip/
日更小说网站: https://024novel.com/
AI汇聚信息:https://info.vi-wealth.com/information
纸鹤漂流来信:https://findingx.us
时间雨:逆滩 · 时雨,https://letter.findingx.us/
AI编程套餐
MiniMax:Coding plan
🎁 MiniMax 跨年福利来袭!邀好友享 Coding Plan 双重好礼,助力开发体验! 好友立享 9折 专属优惠 + Builder 权益,你赢返利 + 社区特权! 👉 立即参与:https://platform.minimaxi.com/subscribe/coding-plan?code=5oAzx7O6Sr&source=link

GLM: coding plan
🚀 速来拼好模,智谱 GLM Coding 超值订阅,邀你一起薅羊毛!Claude Code、Cline 等 20+ 大编程工具无缝支持,“码力”全开,越拼越爽!立即开拼,享限时惊喜价! 链接:https://www.bigmodel.cn/glm-coding?ic=RTWWS8HOD6

火山方舟:特惠编程plan
方舟 Coding Plan 支持 Doubao、GLM、DeepSeek、Kimi 等模型,工具不限,现在订阅折上9折,低至8.9元,订阅越多越划算!立即订阅:https://volcengine.com/L/vd1xvW2KKgg/ 邀请码:2DSAD6JL

轻量云主机长期优惠
RackNerd
☁ 主机显示特惠:只要80元(3TB流量,1vcpu,50GB硬盘) 购买地址:https://my.racknerd.com/aff.php?aff=14942
CloudCone
CloudCone 特惠轻量云主机:购买地址:https://app.cloudcone.com/?ref=12332

📢 腾讯云资源限时福利
有云服务器、CDN、对象存储、网络防护等需求的朋友,欢迎联系下方腾讯云官方销售 👇
✔️ 内部专属折扣,价格更优 ✔️ 量大可谈,支持定制方案 ✔️ 技术咨询与售后无忧
