过去我们谈 AI Agent,经常把注意力放在模型本身:模型够不够强?上下文够不够长?推理能力够不够好?工具调用是不是准确?
但我越来越觉得,真正决定 Agent 能不能稳定工作的,不仅仅是模型,也需要模型外面那一整套 harness 工程。尤其是我们在使用能力较差的模型,harness就是必不可少的工程。
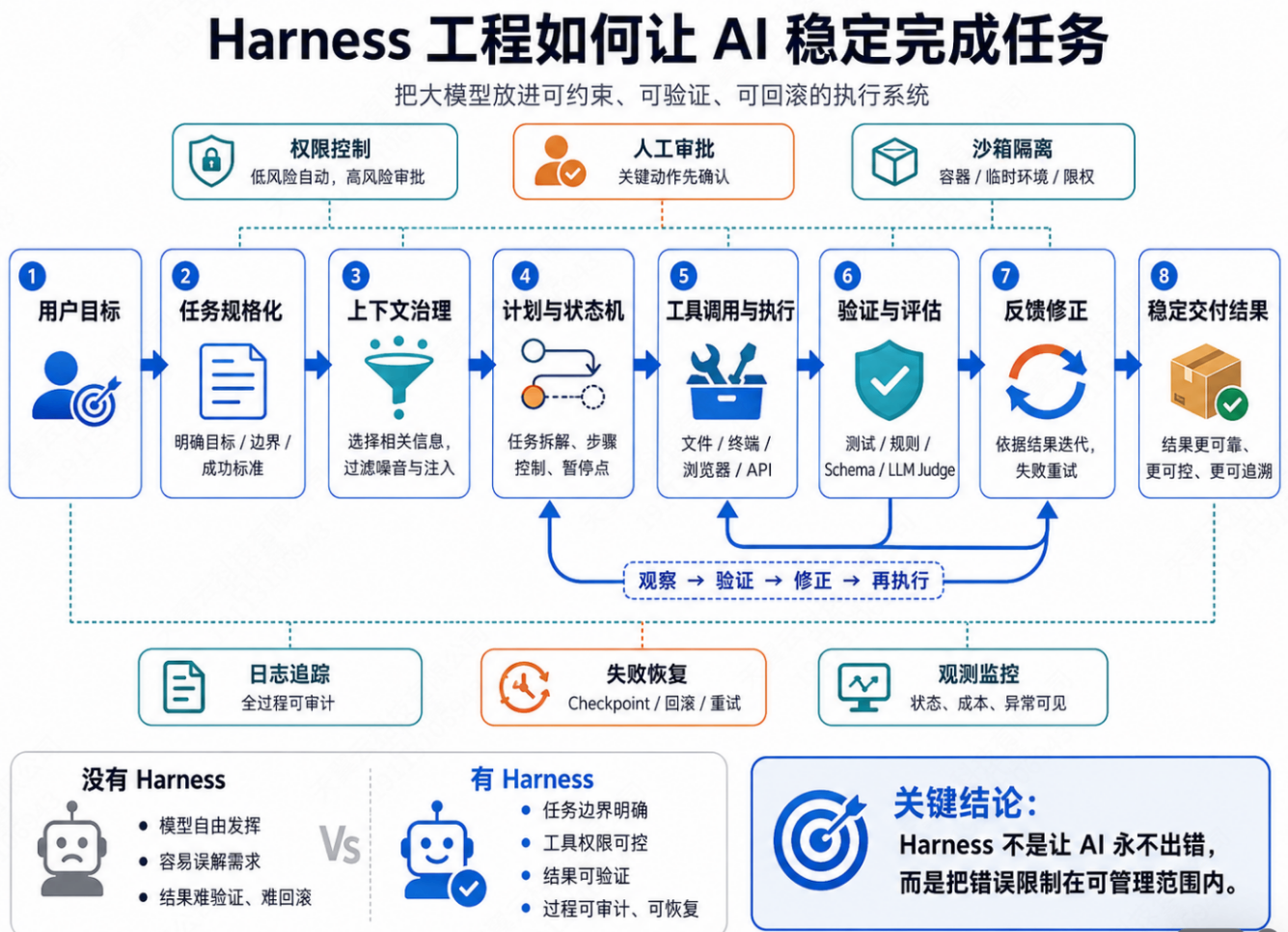
所谓 harness,可以理解成"套在 AI 外面的执行控制层"。它像安全带、轨道、仪表盘和刹车系统的组合:不是让 AI 天生不犯错,而是让 AI 的行动被约束、被观察、被验证、被暂停、被回滚。
我的核心观点是:
harness 工程不能保证 AI 永远不走偏,但它能把 AI 从"自由发挥的概率模型",变成一个"有边界、可验证、可审计、可恢复的工程系统"。
这才是 AI Agent 真正进入生产环境的关键。
harness 工程能让 AI 更按预期工作,不是因为它消除了模型的不确定性,而是因为它用任务规格、上下文治理、工具权限、状态机、验证器、审批、沙箱、日志和恢复机制,把不确定性关进了可管理的工程边界里。
一、裸模型为什么容易走偏
如果我们直接把任务交给大模型,流程通常是这样的:
用户目标 → 模型理解 → 模型生成 → 模型执行 / 输出
这个过程看起来简单,但问题很多。
比如你说:
帮我优化这个项目
模型可能理解成:
- 重构代码
- 升级依赖
- 删除旧文件
- 改配置
- 改数据库 schema
- 重写项目结构
这些动作不一定错,但可能不是你想要的。
再比如你让 Agent 读一个网页,它可能把网页里的恶意提示当成用户指令;你让 Agent 操作终端,它可能执行危险命令;你让 Agent 修改代码,它可能没有跑测试就说"已完成"。
这就是裸模型的核心问题:它能生成行动,但缺少工程边界。
没有 harness 的 AI,就像一个很聪明但没有流程意识的实习生。它可能很快、很积极、很有创造力,但也可能越权、误解、跳步、幻觉、自信地犯错。
二、harness 工程到底是什么
我对 harness 工程的理解是:
harness 工程,就是在模型外部构建一套控制系统,让 AI 的输入、上下文、工具、权限、流程、验证、日志和恢复都被工程化管理。
它不是一个单独的 prompt,也不是一个单独的框架,而是一整套系统设计。
一个典型的 harness 至少包括这些部分:
- 任务规格:明确 AI 要做什么、不能做什么
- 上下文选择:决定 AI 能看到哪些材料
- 工具权限:限制 AI 能调用什么工具
- 状态机:规定任务执行步骤
- 验证器:检查结果是否真的正确
- 人工审批:高风险动作前暂停
- 沙箱隔离:限制错误的破坏范围
- 日志追踪:记录全过程
- 失败恢复:出错后可以回滚和重试
也就是说,harness 不是让 AI "更聪明",而是让 AI 更可控。
三、第一层保证:把模糊目标变成任务规格
AI 走偏的第一类原因,是目标太模糊。
比如:
帮我修复登录问题
这句话对人来说可能够了,但对 Agent 来说太开放了。
更好的 harness 会把它变成任务规格:
goal: 修复登录失败问题
scope:
- 只能修改 auth 模块
- 不能修改数据库 schema
- 不能升级主框架版本
success_criteria:
- 单元测试通过
- 登录接口返回 200
- 原有注册流程不受影响
forbidden_actions:
- 删除用户数据
- 修改生产配置
- 提交到 main 分支
approval_required:
- 安装新依赖
- 修改认证策略
- 修改环境变量
这一步非常关键。
因为 AI 不怕复杂任务,AI 怕的是边界不清楚。边界越模糊,模型自由发挥的空间越大;自由发挥空间越大,走偏概率越高。
harness 的第一件事,就是把自然语言愿望压缩成可执行的任务合同。
四、第二层保证:只给 AI 正确的上下文
很多 Agent 失败,不是因为模型不够强,而是因为它看错了材料。
上下文有三种常见问题:
- 上下文太少:模型缺关键信息,只能猜
- 上下文太多:模型被噪音淹没,抓错重点
- 上下文不可信:模型把网页、文档、日志里的恶意内容当成指令
所以 harness 需要做 context engineering。
它不是简单地把所有文件、所有历史、所有网页都塞给模型,而是要决定:
- 哪些上下文和当前任务相关
- 哪些上下文可信
- 哪些上下文只是参考资料
- 哪些上下文不能当成指令
- 哪些长期规则必须始终保留
- 哪些临时信息可以被压缩或丢弃
我通常会把上下文分成三层:
- 稳定规则层:项目规范、安全边界、编码约定、禁止动作
- 任务工作层:当前任务相关文件、日志、接口文档、错误信息
- 短期运行层:最近几步工具结果、测试输出、审批状态、验证结果
这就是为什么优秀的 Agent 系统越来越重视 memory、context file、repo map、session、checkpoint 和工具结果标注。
AI 的输入质量,决定了它的行为质量。
五、第三层保证:限制 AI 能调用的工具
如果 AI 只能聊天,风险相对有限。
但一旦 AI 能调用工具,问题就完全不同了。
它可能能做这些事:
- 读文件
- 写文件
- 执行 shell
- 调用浏览器
- 访问数据库
- 发邮件
- 调用 API
- 提交代码
- 发布服务
这时,harness 必须把"模型想做什么"和"系统允许做什么"分开。
模型可以提出行动建议,但真正执行前,要经过权限策略。
例如:
tools:
read_file:
risk: low
mode: auto_allow
run_tests:
risk: low
mode: auto_allow
edit_file:
risk: medium
mode: allow_in_workspace
install_dependency:
risk: medium
mode: require_approval
delete_file:
risk: high
mode: require_approval
deploy_production:
risk: critical
mode: deny
这就是工具权限控制的本质:
AI 可以建议,但不能无限制执行。
好的 harness 不会把整个终端、整个文件系统、整个生产 API 都交给模型,而是通过 allowlist、denylist、风险分级、审批机制和沙箱,把工具能力收窄到任务需要的范围。
六、第四层保证:用工作流约束执行顺序
没有 harness 的 Agent,常常会这样做事:
理解一点点 → 直接动手 → 中途猜测 → 最后自信总结
这在人类看来很危险。
更好的方式,是把任务拆成明确流程:
理解需求
→ 收集上下文
→ 制定计划
→ 等待确认
→ 执行最小修改
→ 运行验证
→ 失败归因
→ 修复
→ 再验证
→ 输出总结
这就是状态机和工作流的价值。
模型不再决定所有流程,而是被放进一个预设轨道里。
比如代码修复任务,可以强制规定:
- 第一步:复现问题
- 第二步:定位原因
- 第三步:提出最小修改方案
- 第四步:修改代码
- 第五步:运行测试
- 第六步:输出 diff 和验证结果
如果模型没有复现问题,就不能直接修改代码;如果测试没有通过,就不能宣称完成;如果涉及高风险文件,就必须暂停审批。
这类流程约束,就是 harness 让 AI "按预期工作"的核心机制之一。
七、第五层保证:用验证器代替"模型自我宣布完成"
AI Agent 最不可靠的一句话是:
我已经完成了。
因为它可能没有真的完成。
它可能没有跑测试,没有打开页面,没有验证接口,没有检查边界条件,只是根据自己的推理觉得"应该没问题"。
所以 harness 必须引入验证器。
验证器可以是:
- 单元测试 / 集成测试
- lint / 类型检查
- 构建检查
- 接口 contract 测试
- schema 校验
- diff 范围检查
- 安全规则检查
- LLM judge
- 人工评审
对于代码任务,可以这样验证:
npm test
npm run lint
npm run build
pytest
对于接口任务,可以这样验证:
curl /health
curl /api/login
contract-test
对于结构化输出,可以这样验证:
- 必须符合 JSON Schema
- 必须包含指定字段
- 不能出现空值
- 不能引用不存在的来源
这一步的核心思想是:
不相信 AI 的自我声明,只相信可验证的证据。
harness 把"输出结束"变成"验证通过",这是 AI Agent 从演示走向生产的关键。
八、第六层保证:高风险动作必须人工审批
真正的生产级 Agent,不应该完全自动化。
至少这些动作应该需要人工确认:
- 删除文件
- 安装依赖
- 修改配置
- 访问生产数据库
- 发送邮件
- 发布上线
- 提交 PR
- 调用支付接口
- 修改权限
- 操作客户数据
这不是因为 AI 一定会犯错,而是因为这些动作的错误成本太高。
好的 harness 会设计 approval gate:
- 低风险动作:自动执行
- 中风险动作:展示计划后执行
- 高风险动作:必须人工确认
- 禁止动作:直接拒绝
但这里有一个细节:审批不能太频繁。
如果每一步都弹窗,人会疲劳,最后机械地点"同意"。真正有效的审批,应该满足四个条件:
- 审批对象明确
- 审批时机稀缺
- 审批信息充分
- 审批结果可审计
也就是说,harness 不是让人类重新接管所有任务,而是在关键风险点设置硬刹车。
九、第七层保证:沙箱限制错误的破坏范围
即使有任务规格、权限控制、验证器和审批,AI 仍然可能犯错。
所以还需要沙箱。
沙箱的作用不是让 AI 不犯错,而是限制犯错后的损失。
比如:
- 在 Docker 容器里执行代码
- 只挂载当前工作目录
- 不挂载 SSH key
- 不挂载生产配置
- 默认关闭外网
- 限制 CPU 和内存
- 使用临时 token
- 使用测试数据库
这样,即使 Agent 执行了危险命令,影响也被限制在容器或临时环境里。
这就像汽车安全设计:
- 刹车系统用于避免事故
- 安全带和气囊用于事故发生后降低伤害
harness 里的权限控制和审批是刹车,沙箱是安全带和气囊。
十、第八层保证:全过程可观测、可审计
如果 AI 做错了,最可怕的不是错,而是不知道它为什么错。
所以 harness 必须记录执行轨迹。
一次完整的 Agent run,至少应该记录:
- 用户原始需求
- 任务规格
- 使用了哪些上下文
- 模型每一步计划
- 调用了哪些工具
- 工具输入是什么
- 工具输出是什么
- 权限策略如何判断
- 哪些动作被审批
- 验证器结果
- 最终产物
- 失败原因
- 回滚状态
这类日志可以写成 JSONL:
{
"run_id": "agent-run-001",
"step": "before_tool_call",
"agent": "coder",
"tool": "execute_bash",
"proposal": {
"command": "pytest -q",
"cwd": "/workspace/app"
},
"policy": {
"risk": "low",
"decision": "auto_allow"
},
"validator": {
"name": "pytest",
"status": "pass",
"evidence": "12 passed"
},
"result": {
"status": "success"
}
}
有了这些记录,团队才能回答:
- 它为什么这么做?
- 它看了哪些文件?
- 它有没有越权?
- 它在哪一步失败?
- 是模型问题、上下文问题、工具问题,还是验证器问题?
没有可观测性,就没有真正的可靠性。
十一、第九层保证:失败后可以恢复,而不是从头乱试
Agent 任务越长,越容易遇到失败:
- 工具超时
- 上下文丢失
- 测试失败
- 权限不足
- 外部 API 报错
- 模型误解
- 用户中途修改需求
如果没有 harness,失败后通常只能重新来一遍。
但生产级 harness 应该支持:
- checkpoint
- resume
- retry
- rollback
- fork
- time travel
- state replay
比如:
执行到第 7 步失败
→ 回到第 5 步 checkpoint
→ 补充上下文
→ 修改计划
→ 继续执行
这和传统软件系统里的事务、快照、日志回放很像。
关键不是让 AI 永远成功,而是让它失败后不会乱掉。
十二、harness 的本质:把 AI 变成受控系统
如果从控制论角度看,裸模型是一个开放回路:
输入 → 模型 → 输出
harness 则把它变成闭环系统:
目标 → 计划 → 执行 → 观察 → 验证 → 反馈 → 修正 → 再执行
这就是区别。
- 裸模型依赖一次性生成;harness 依赖持续反馈。
- 裸模型靠"模型觉得对";harness 靠"外部验证通过"。
- 裸模型自由调用工具;harness 让工具调用经过权限策略。
- 裸模型说完成就完成;harness 要求证据。
- 裸模型出错难追踪;harness 全程留痕。
这就是为什么 harness 工程能显著提高 AI 按预期工作的概率。
十三、但 harness 不是万能保证
这里必须说清楚:harness 不能提供数学意义上的绝对保证。
AI 仍然可能:
- 误解任务
- 引用错误上下文
- 被 prompt injection 影响
- 错误规划
- 忽略工具反馈
- 生成错误代码
- 通过不完善的验证器
- 在长任务中目标漂移
尤其在开放网络、第三方文档、MCP 工具链、多 Agent 协作、生产系统访问这些场景里,风险仍然存在。
所以更准确的说法不是:
harness 保证 AI 不会走偏
而是:
harness 把 AI 走偏的概率降低;
把 AI 走偏的范围缩小;
把 AI 走偏的过程记录下来;
把 AI 走偏后的恢复路径变短。
这已经是巨大的工程进步。
十四、我推荐的 harness 工程落地清单
如果我要在一个真实项目里引入 AI Agent,我会按这个顺序做:
| 阶段 | 要做什么 | 交付物 |
|---|---|---|
| 任务规格 | 明确目标、边界、完成条件、禁止动作 | SPEC.md |
| 上下文治理 | 区分规则、资料、工具结果、临时状态 | AGENTS.md / context config |
| 工具权限 | 给每个工具设置风险等级和审批策略 | policy.yaml |
| 沙箱隔离 | 默认容器执行,限制文件和网络权限 | docker-compose.yml |
| 验证器 | 加入测试、schema、lint、安全检查 | verify.sh |
| 审批机制 | 高风险动作前暂停 | approval gate |
| 状态持久化 | 保存 checkpoint 和 session | state store |
| 日志追踪 | 记录模型、工具、策略、验证结果 | audit.jsonl |
| 回滚机制 | 支持 git、数据库、状态回滚 | rollback plan |
| 回归评测 | 每次更新 harness 都跑 eval | evals/ |
如果一个 Agent 系统没有这些东西,我不会把它当生产系统,只会把它当 demo。
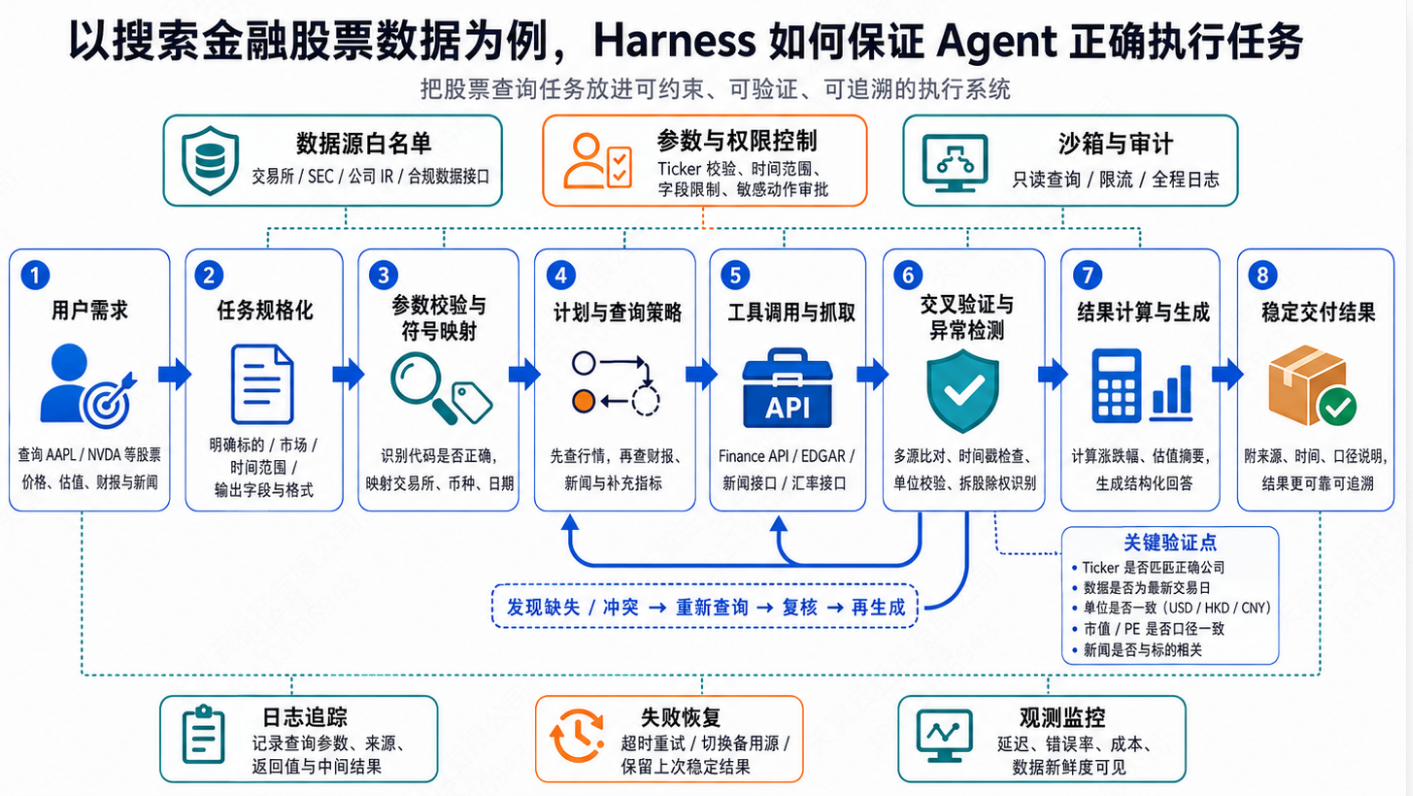
十五、一个简单例子:让 AI 修 bug
普通方式可能是:
帮我修复这个 bug
harness 化之后应该是:
任务:修复登录接口返回 500 的问题。
限制:
1. 只能修改 src/auth 目录;
2. 不能修改数据库 schema;
3. 不能安装新依赖;
4. 不能访问生产环境;
5. 修改前先说明计划;
6. 修改后必须运行测试。
验证:
1. pytest tests/auth 通过;
2. lint 通过;
3. 登录接口 contract test 通过;
4. 输出最终 diff 和测试结果。
这时,AI 的自由度被大幅压缩。
它仍然可以思考、搜索、修改、调试,但必须在明确轨道里行动。
这就是 harness 的价值。
十六、为什么这会成为 AI Agent 的核心工程方向
我认为未来 AI Agent 的竞争,不会只是谁的模型更强,而是谁的 harness 更成熟。
因为模型能力会越来越接近,真正拉开差距的是:
- 谁能更好地管理上下文
- 谁能更安全地接工具
- 谁能更稳定地跑长任务
- 谁能更清楚地审计过程
- 谁能更可靠地验证结果
- 谁能更快地从失败中恢复
- 谁能更低成本地把 Agent 放进生产系统
这也是为什么 LangGraph、CrewAI、OpenHands、Hermes Agent、Google ADK、Semantic Kernel、Strands Agents、OpenAI Agents SDK、MCP 等生态都在往同一个方向演进:状态、工具、权限、审批、观测、评测、沙箱、协议化。
AI Agent 的下半场,不只是模型战争,而是 harness 工程战争。
结语:不要只问模型强不强,要问系统稳不稳
过去我们习惯问:
这个模型聪明吗?
但在 Agent 时代,更重要的问题应该是:
这个系统能不能被约束?
能不能被验证?
能不能被暂停?
能不能被审计?
能不能被回滚?
能不能在失败后继续?
harness 工程的意义就在这里。
它不是让 AI 变成绝对可靠的机器,而是把 AI 放进现代软件工程的控制结构里。
一句话总结:
harness 工程能让 AI 更按预期工作,不是因为它消除了模型的不确定性,而是因为它用任务规格、上下文治理、工具权限、状态机、验证器、审批、沙箱、日志和恢复机制,把不确定性关进了可管理的工程边界里。
这才是 AI Agent 真正可用、可控、可上线的开始。